
1. Einleitung
Die Entwicklung und Verbreitung von Large Language Models (LLMs) hat das Potenzial, die Interaktion des Menschen mit digitalen Systemen grundlegend zu verändern. Diese Modelle, wie Gemini von Google, sind in der Lage, menschenähnliche Texte zu generieren, komplexe Anfragen zu verarbeiten und durch maschinelles Lernen eine hohe Adaptivität an die individuellen Bedürfnisse der Nutzer zu entwickeln. Das Kernversprechen dieser Technologien liegt in der Personalisierung des Benutzererlebnisses, die durch das Sammeln und Analysieren von Nutzerdaten erreicht wird. Doch diese tiefgreifende Personalisierung birgt erhebliche datenschutzrechtliche und ethische Herausforderungen (European Data Protection Board, 2020). Dieser Artikel untersucht die Mechanismen der Datenerfassung durch LLMs, die Gestaltung der Nutzerzustimmung und die daraus resultierenden Implikationen für den Schutz der Privatsphäre.
2. Datenerfassung durch LLMs: Der Fall Google Gemini
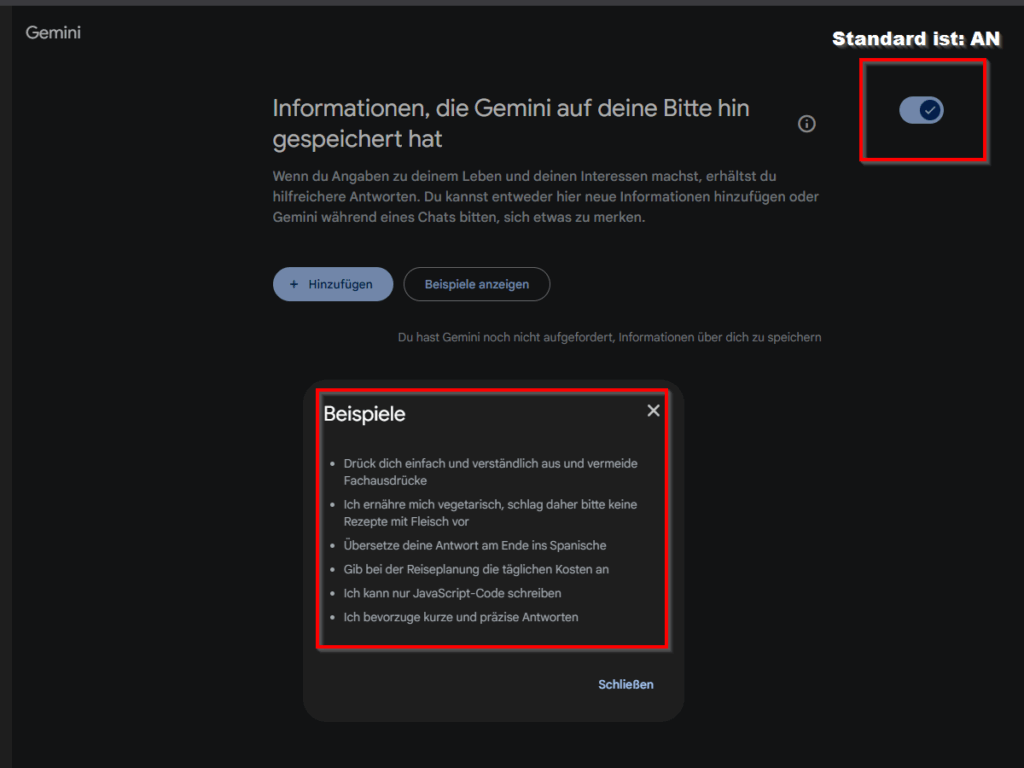
Das LLM Gemini, entwickelt von Google, demonstriert exemplarisch die tiefgreifende Datenerfassung, die oft standardmässig in modernen KI-Anwendungen implementiert ist. Gemini ist darauf ausgelegt, unaufgefordert Eigenschaften ihrer Benutzer zu sammeln, detaillierte persönliche Profile zu erstellen und dieses Wissen in zukünftigen Interaktionen zu nutzen. Diese Datenerfassung umfasst nicht nur explizit vom Nutzer eingegebene Informationen, sondern auch implizite Daten, die aus dem Interaktionsverhalten abgeleitet werden, wie z.B. bevorzugte Themen, Schreibstile, emotionale Reaktionen und sogar sensible persönliche Details, die beiläufig in Prompts erwähnt werden.

Die gesammelten Informationen dienen nicht nur der Verbesserung der LLM-Leistung im spezifischen Kontext der Benutzerinteraktion. Vielmehr werden diese umfassenden Profile von Google auch für weitere kommerzielle Zwecke genutzt, darunter gezielte Werbung, personalisierte Anzeigen auf Webseiten und massgeschneiderte Angebote in anderen Produkten des Konzerns (siehe nächste Abbildung). Dieses „Profiling“ ermöglicht eine hochgradig individualisierte Ansprache des Nutzers, birgt aber gleichzeitig erhebliche Risiken für die informationelle Selbstbestimmung.

3. Die Komplexität der Nutzerzustimmung und Informationsasymmetrie
Ein zentraler Aspekt der datenschutzrechtlichen Bewertung ist die Einholung der Nutzerzustimmung. Im Fall von Gemini wird die Zustimmung durch eine komplexe und umfangreiche Einleitungserklärung vor der ersten Nutzung eingeholt (siehe Abbildung zuvor). Diese Erklärung ist oft in einem juristischen Fachjargon verfasst, beinhaltet zahlreiche Verweise auf weitere Dokumente und ist für den durchschnittlichen Nutzer nur schwer verständlich. Die schiere Menge an Informationen und die Notwendigkeit, multiple Links zu verfolgen, um die volle Tragweite der Zustimmung zu verstehen, führt dazu, dass viele Nutzer diese Erklärungen nicht vollständig lesen und somit die Konsequenzen ihrer Zustimmung nicht vollständig erfassen (OECD, 2021).

Diese Praxis schafft eine erhebliche Informationsasymmetrie zwischen dem Anbieter und dem Nutzer. Während der Anbieter detaillierte Kenntnisse über die Datenerfassung und -verwendung besitzt, ist der Nutzer oft unzureichend über die Risiken und den Umfang der Preisgabe seiner persönlichen Informationen aufgeklärt. Die formelle Zustimmung des Nutzers, die durch das Akzeptieren der Nutzungsbedingungen erfolgt, entbindet den Anbieter rechtlich von der Haftung im Sinne der Datenschutzbestimmungen, wie der Datenschutz-Grundverordnung (DSGVO) in der Europäischen Union (Verordnung (EU) 2016/679) oder dem revidierten Schweizer Datenschutzgesetz (revDSG) (SR 235.1).
4. Rechtliche Rahmenbedingungen und ihre Grenzen
Die DSGVO und das revDSG stellen hohe Anforderungen an die Verarbeitung personenbezogener Daten, insbesondere im Hinblick auf die Rechtmässigkeit der Verarbeitung, die Transparenz und die informationelle Selbstbestimmung. Gemäss Artikel 6 Abs. 1 lit. a DSGVO ist die Einwilligung des Nutzers eine zentrale Rechtsgrundlage für die Datenverarbeitung. Diese Einwilligung muss jedoch „freiwillig, für den bestimmten Fall, in informierter Weise und unmissverständlich“ erfolgen (Artikel 4 Abs. 11 DSGVO). Die Komplexität der Nutzungsbedingungen, wie im Fall von Google Gemini, wirft die Frage auf, ob die informierte Weise stets gegeben ist, wenn die Informationen so gestaltet sind, dass sie nur schwer zugänglich sind (Council of Europe, 2017).
Obwohl Google die rechtlichen Rahmenbedingungen formal einhält, indem es die Datenerfassung in seinen Nutzungsbedingungen und Datenschutzbestimmungen offenlegt, stellt die Art und Weise der Kommunikation eine Herausforderung für den Verbraucherschutz dar. Das Risiko, dass Nutzer unwissentlich sensible Daten preisgeben und diese für Zwecke verwendet werden, die über die ursprüngliche Erwartung hinausgehen, bleibt hoch. Dies unterstreicht die Notwendigkeit einer stärkeren Betonung der Nutzeraufklärung über die Risiken des Promptings und der Interaktion mit LLMs.
5. Risiken, die aus den Implikationen für Unternehmen entstehen
Das Problem von „Shadow IT“, bei dem Mitarbeiter ohne offizielle Genehmigung oder Kontrolle LLMs für geschäftliche Zwecke nutzen, verschärft alle oben genannten Risiken. Wenn Unternehmen keine klaren Richtlinien und technischen Kontrollen implementieren, können Mitarbeiter unbewusst oder fahrlässig Unternehmensdaten gefährden.
Konkrete Beispiele, in dem Unternehmensdaten dauerhaft durch LLMs an ihre Hersteller weitergereicht werden können:
- Code-Preisgaben: Ein Entwickler fragt Gemini, wie ein bestimmtes Problem in einem proprietären Code gelöst werden kann, und fügt dabei relevante Code-Snippets ein. Diese könnten, selbst wenn sie nicht direkt in die Trainingsdaten des öffentlichen Modells gelangen, eine Offenlegung gegenüber dem LLM-Anbieter darstellen und potenziell zu unbefugtem Zugriff oder Diebstahl führen.
- Technologieoffenlegungen: Ein Ingenieur beschreibt in einem Prompt eine neue, noch nicht patentierte Technologie oder eine einzigartige Fertigungsmethode, um sich Feedback oder Ideen einzuholen. Die LLM-Anbieter könnten diese Informationen theoretisch nutzen oder sie könnten durch andere Kanäle (z.B. Sicherheitslücken) an Dritte gelangen.
- Interne Strategien oder Finanzdaten: Ein Mitarbeiter fragt nach der Formulierung eines Marketingplans für ein neues Produkt und teilt dabei Details über die Strategie oder finanzielle Eckdaten mit. Dies könnte die Wettbewerbsposition des Unternehmens gefährden.
- Informationen aus strikteren Datenklassifizierungen: Unternehmen haben oft unterschiedliche Datenklassifizierungen (z.B. „öffentlich“, „intern“, „vertraulich“, „streng vertraulich“). Wenn Daten, die als „streng vertraulich“ eingestuft sind (z.B. Kundendaten, Patientendaten, M&A-Informationen), versehentlich in ein LLM eingegeben werden, ist dies ein schwerwiegender Verstoss gegen interne Richtlinien und potenzielle Datenschutzgesetze.
6. Empfehlungen und Fazit
Die Fallstudie von Google Gemini zeigt, dass die blosse formale Einhaltung von Datenschutzgesetzen nicht ausreicht, um die Privatsphäre der Nutzer im Zeitalter der LLMs umfassend zu schützen. Es bedarf einer verstärkten Sensibilisierung und Aufklärung der Öffentlichkeit über die Funktionsweise von LLMs und die Implikationen der Datenerfassung.
Folgende Massnahmen könnten zur Verbesserung der Situation beitragen:
- Vereinfachung von Nutzungsbedingungen: Anbieter sollten auf eine klare, verständliche und prägnante Sprache in ihren Nutzungsbedingungen achten. Wesentliche Informationen zur Datenerfassung sollten leicht zugänglich und visuell hervorgehoben werden (European Consumer Organisation, 2022).
- Gestufte Einwilligung: Anstatt einer „Alles-oder-Nichts“-Zustimmung sollten gestufte Einwilligungsoptionen angeboten werden, die es Nutzern ermöglichen, granularer zu entscheiden, welche Daten für welche Zwecke verwendet werden dürfen.
- Transparenz-Dashboards: Bereitstellung von einfach zugänglichen Dashboards, die Nutzern einen Überblick über die gesammelten Daten und deren Verwendung geben, sowie die Möglichkeit bieten, Einstellungen jederzeit anzupassen.
- Verstärkte Verbraucherbildung: Bildungseinrichtungen und Verbraucherschutzorganisationen müssen ihre Anstrengungen verstärken, um die digitale Kompetenz der Bürger zu fördern und sie über die Risiken und Chancen von KI-Technologien aufzuklären.
- Regulierungs- und Aufsichtsmechanismen: Regulierungsbehörden sollten prüfen, ob die aktuelle Gestaltung von Nutzungsbedingungen den Anforderungen an eine „informierte“ Einwilligung tatsächlich genügt und gegebenenfalls Leitlinien zur besseren Nutzeraufklärung entwickeln.
Die Personalisierung durch LLMs bietet zweifellos enorme Potenziale. Doch die Sicherstellung der informationellen Selbstbestimmung der Nutzer muss dabei oberste Priorität haben. Es ist eine gemeinsame Anstrengung von Entwicklern, Regulierungsbehörden und Nutzern erforderlich, um eine digitale Zukunft zu gestalten, in der Innovation und Privatsphäre Hand in Hand gehen.
Referenzen
- Council of Europe (2017). Guidelines on Artificial Intelligence and Data Protection. [1]
- European Consumer Organisation (BEUC). (2022). Consumer Rights in the Digital Age: Ensuring Fair and Transparent Terms and Conditions. [2]
- European Data Protection Board (EDPB). (2020). Guidelines 4/2020 on the use of cookies and other tracking technologies. [3]
- Google’s Datenschutzerklärung. [4]
- Google’s Nutzungsbedingungen. Abgerufen von [5]
- OECD. (2021). Recommendation on Artificial Intelligence. [6]
- Verordnung (EU) 2016/679 des Europäischen Parlaments und des Rates vom 27. April 2016 zum Schutz natürlicher Personen bei der Verarbeitung personenbezogener Daten, zum freien Datenverkehr und zur Aufhebung der Richtlinie 95/46/EG (Datenschutz-Grundverordnung). [7]
- Bundesgesetz über den Datenschutz (Datenschutzgesetz, DSG) vom 25. September 2020 (SR 235.1), revidierte Fassung. [8]
- Gemini App Hilfe [9]





