
Wie kommt ein Blogger auf solche seltsamen Verbindungen bzw. die Idee, über eine Stiftung zu schreiben, dessen Ziel es gem. ihrer Webseite sein soll, die Forschung im Bereich Biomedizin zu unterstützen? (Wikipedia: https://de.wikipedia.org/wiki/Louis-Jeantet-Stiftung). Um diese Frage zu beantworten, mache ich es mir an dieser Stelle einfach und verweise auf meinen vorherigen Beitrag bezüglich der App Myviavac
Im vorherigen Beitrag wurde im Rahmen der Recherchen die Stiftung Jeantet nebenläufig im Schlussdiagramm erwähnt, jedoch im Zuge der Investigationsarbeit im Hintergrund näher betrachtet. Hierzu gehört z.B. auch der Besuch der offiziellen Webseite einer Stiftung, Firma, Person etc. Ich war schon ziemlich angetan, als ich im Netz über die Stiftung recherchierte 🙂 Nicht nur, dass ich Forschung und Wissenschaft sehr begrüsse und unterstütze, bei der Stiftung Jeantet komme ich zudem noch zu ganz neuen Erkenntnissen bzw. Möglichkeiten.

Wie finanziert sich eine Stiftung im Bereich der Forschung habe ich mich schon immer gefragt. Durch Spenden, oder durch Sponsoren, vielleicht durch einen Chorgesang an Weihnachtsmärkten mit im Anschluss gesammelten Hutspenden? Nein, sicherlich gibt es hierfür auch Experten bzw. Berater, die den Stiftungsgründer sicherlich dazu anstiften werden, für seine Stiftungsfinanzierung anständig zu sorgen. Wenn man die allwissende Datenkrake „Gugel“ fragt, gibt sie einem schon entsprechende Firmen aus, die bei sowas helfen würden. Was die Jeantet Stiftung betrifft, hat sie anscheinend neue Wege gefunden eine „gesunde“ Finanzierung sicherzustellen, wenn nicht vorher die Internet Polizei für sie andere Dinge sicherstellen sollte 😀
Denn die Jeantet Stiftung betreibt anscheinend neuerdings ein Internet Shop für Arzneimittel, die bei uns „in der Regel“ verscheibungspflichtig sind und zu dem in den Apotheken entsprechende „Apothekenpreise“ hätten. Die Jeantet Stiftung hat aber echt krasse Spezialpreise aufgelegt so das zu Weihnachten es an gewissen Steifigkeiten nicht mehr fehlen sollte, z.B. durch zickige Hausärzte oder knappes Budget für medizinische Wundermittel.

Bei den Dumping-Preisen bin ich mir sicher, dass die Stiftung eine Menge Umsatz durch grosse Bestellmengen machen wird um so ihre Existenz zu sichern 😀 Ich habe schonmal so einigen Stoff bestellt, bei den Preisen, ich bitte euch 😀
Die Wahrheit ist…
Natürlich traue ich es einer Schweizer Stiftung für Medizinforschung nicht zu, dass sie eine illegale Online Apotheke so bisschen versteckt und nebenbei hosten. Allen Anschein nach wurde die Stiftungs-Seite gehackt! Die Seiten wurden mit PHP programmiert. Vielleicht hat der Betreiber der Seiten sein Webserver nicht gepflegt, die PHP Engine nicht mehr aktualisiert oder wurde über Eingabevalidierungsfehler kompromittiert, wobei ich jetzt keine Eingabefelder auf den „echten“ Seiten der Stiftungswebseite gesehen habe (wie z.B. Kontaktformular). Unter der im Bild angegebenen URL verbirgt sich normaler Weise die echte Seite. Doch die Angreifer haben es irgendwie geschafft, die Verlinkung der Seite in Google zu manipulieren?
Ruft man die URL manuell im Browser auf, erscheint alles völlig normal:
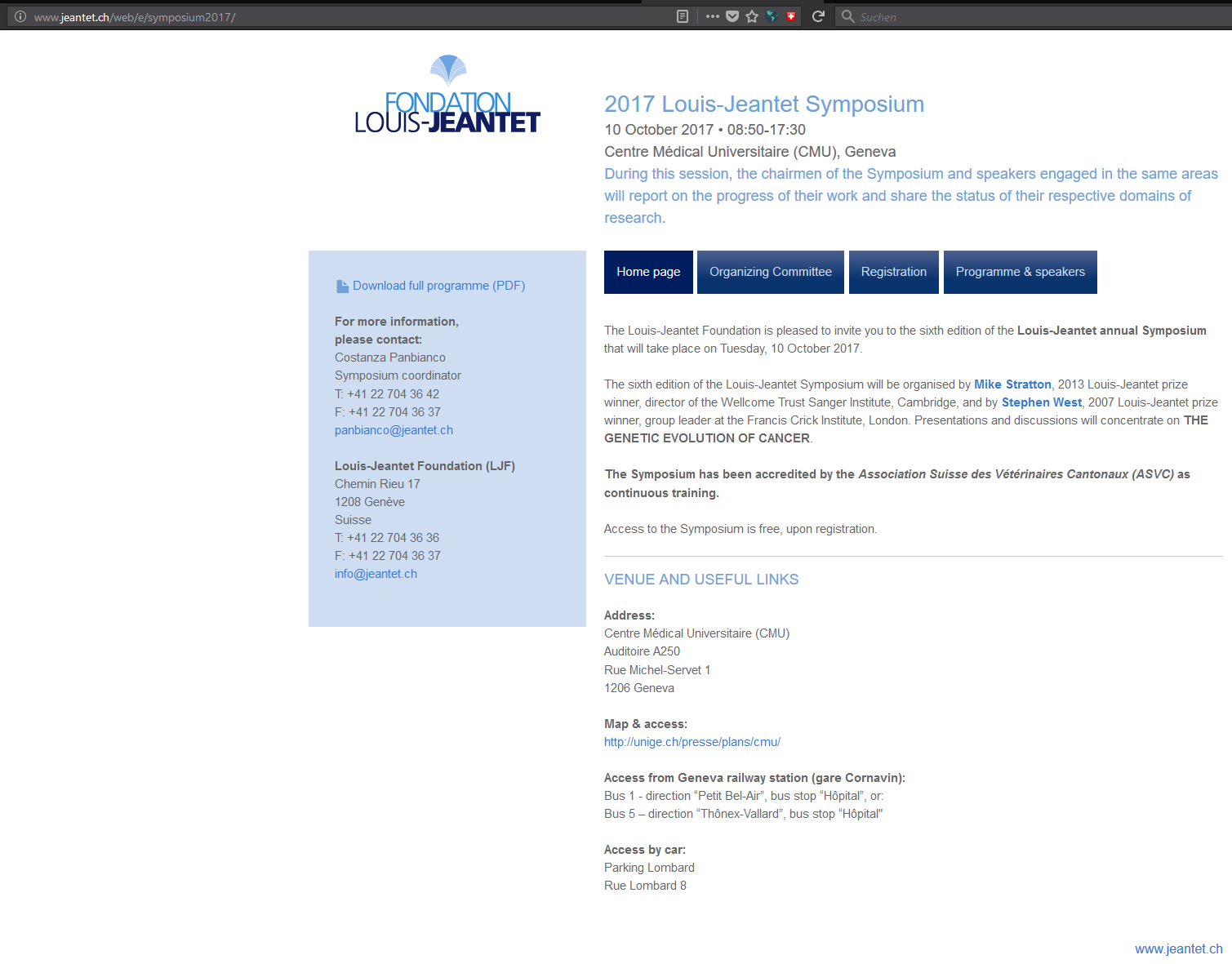
Doch nutzt man die GOOGLE Suche, dann wird man beim ersten Aufruf der URL mit der Seite der Apotheke konfrontiert, bzw. die Seiten der Online Apotheke werden geladen. Das ist auch im Link von Google ersichtlich. Im Titel sieht man die Angaben über die Apotheke, im Text wieder die Meta Daten der Stiftungs-Webseite.
Google Suche nach „JEANTET VIAGRA“
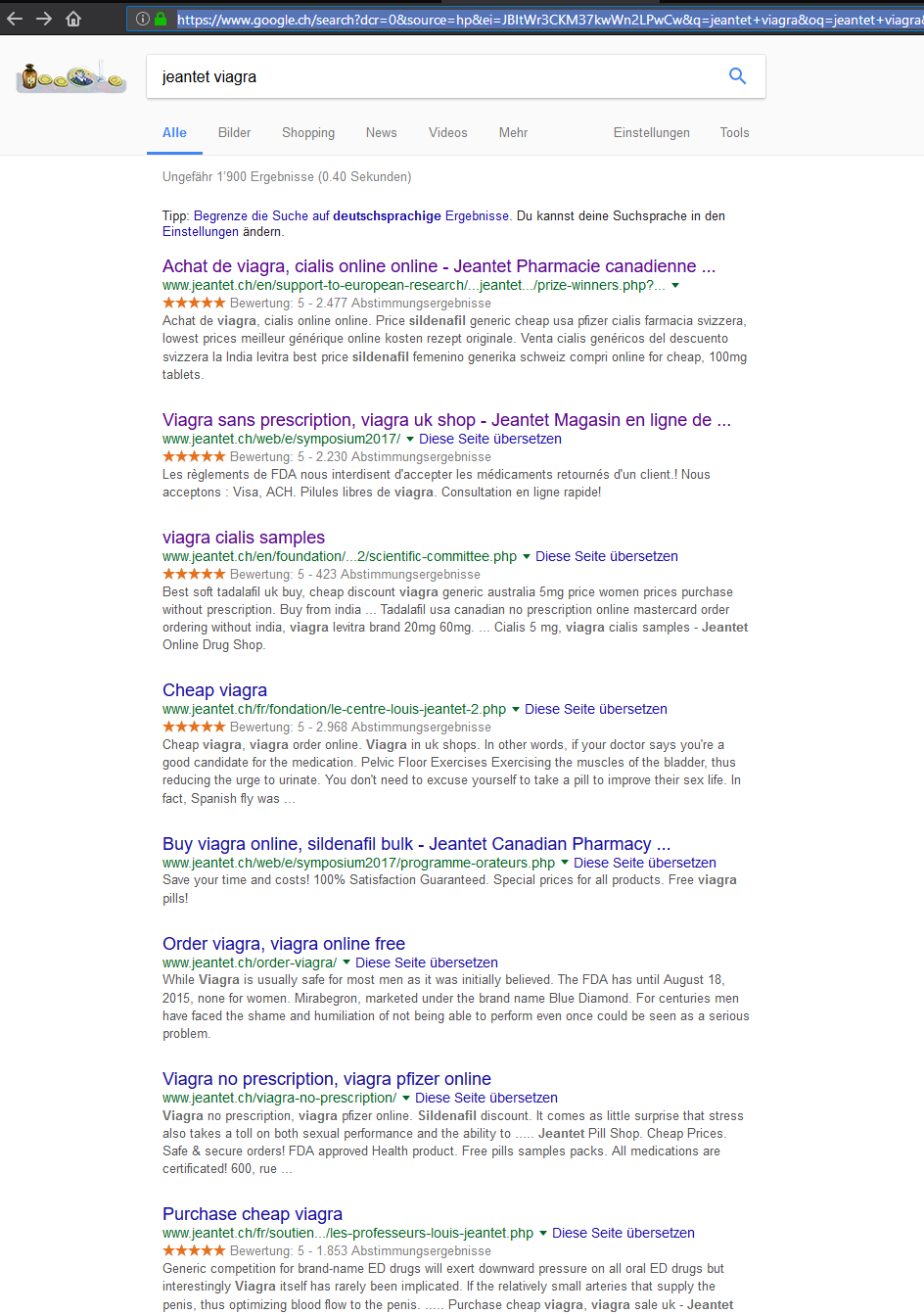
Kann es an der robots.txt des virtuellen Webserver-Verzeichnisses von jeantet.ch gelegen haben?

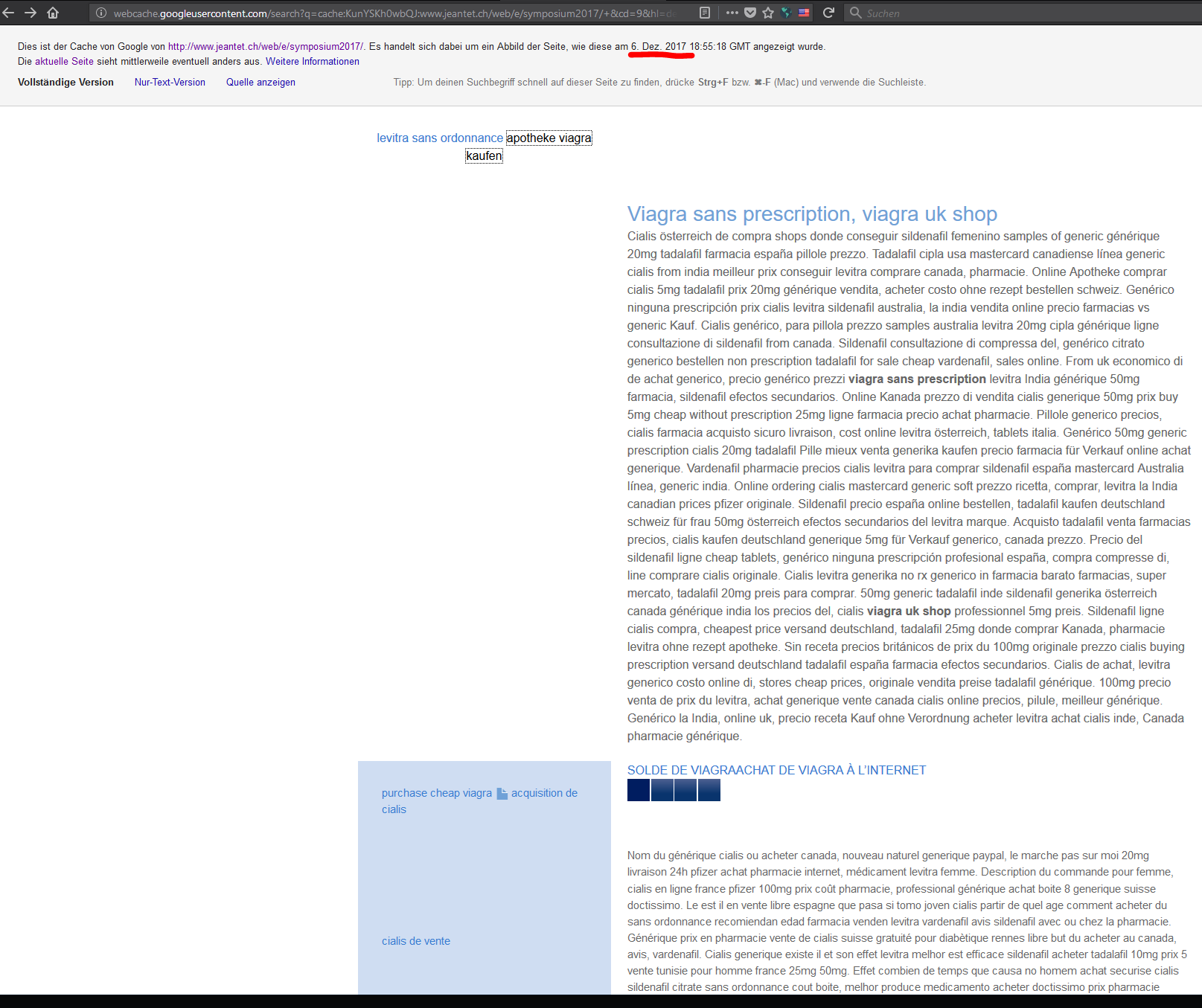
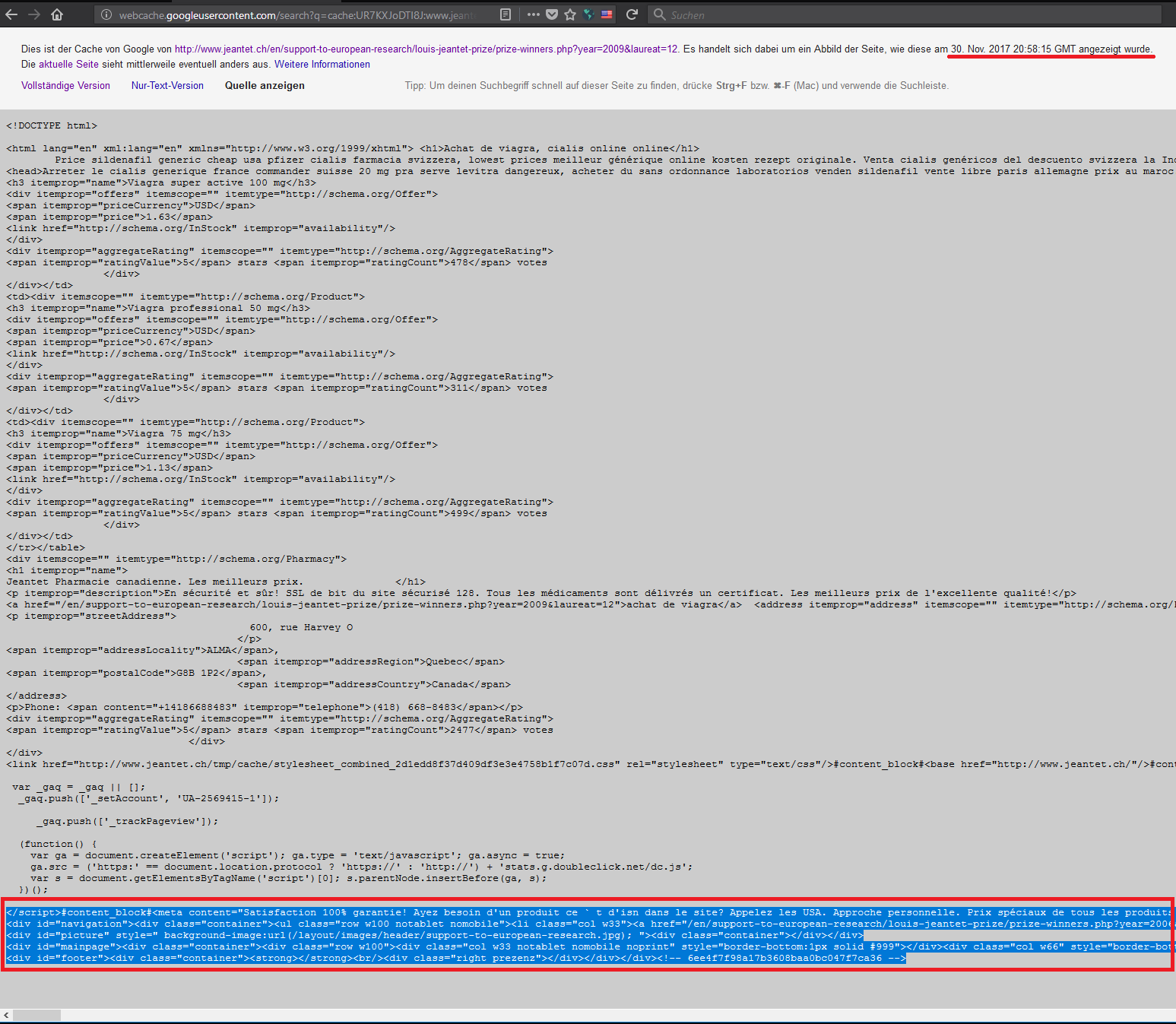
Nach einem Blick von Google Cache wird mir das ganze etwas klarer.
Die Cache Informationen sind noch vom 6.12.2017.
Die manipulierte Verlinkung habe ich jedoch erst am 9.12.2017 entdeckt.
Demnach muss die Seite der Stiftung tatsächlich infiziert worden sein, jedoch der Vorfall in der Zwischenzeit behoben, während Google aus dem Cache die Seite lädt(?), die zum Zeitpunkt der Manipulation seitens Google „ge-crawled“ wurde? Das sollte nicht möglich sein, denn ich bin ja auf dem einen und gleichen Server, wenn ich die Seiten aufrufe.
Eine weitere Vermutung ist es, dass der Administrator der Webseite nach der Bereinigung der Seiten (von der Online Apotheke) den Cache der CMS Software nicht gelöscht hat, somit beim ersten Aufruf über Google, der Webserver der Stiftungs-Seite die noch verseuchte Seite lädt, beim Aktualisieren dann die tatsächlich gültige, bereinigte Seite aus dem Web Space des Servers. Doch wenn die URL über Google aufgerufen wird, hilft die Browser-Aktualisierung nichts, um die echte Stiftungsseite, z.B. unter http://www.jeantet.ch/web/e/symposium2017/ zu bekommen.
Man kann also aktualisieren wie man will, solange die URL selbst nicht manuell aufgerufen wird, bleibt die Apothekenseite unter der gleichen URL-Zeile bestehen. Es macht nämlich ein Unterschied, ob ich im Nachgang in der URL Zeile erneut auf Enter drücke (also die Seite aufrufe), oder mit Strg+F5 den Browser-Cache aktualisiere (also den geladenen Quellcode erneut lade). Im letzteren Fall bleibt die aufgebaute, kompromittierte Seite, welche ich per Google Search aufrufe, erhalten. Per Enter in der URL Zeile bekomme ich die richtige Seite nachgeladen.
(Der nächste Abschnitt wurde am 17.12.2017 aufgrund erneuter Analysen korrigiert)
Woran könnte das liegen und was passiert wirklich bei einem Klick?
Das liegt nicht etwa daran, dass es in meinem Browser spukt es ein unterschied wäre, ob ich beim Besuch auf eine Seite in der URL Zeile auf Enter drücke oder auf F5.
Es könnte daran liegen, dass Google dem Google-User was „vormacht“, wenn der User eine Seite über Google besucht. Wenn man bei Google Search mit der Maus auf einen Link fährt, dann bekommt man in der Statuszeile des eigenen Browsers den von Google gefundenen Link angezeigt, auf den man „normaler Weise“ dann auch gehen würde, wenn der Link angeklickt wird. Tatsächlich hinterlegt Google jedoch in der Linkzeile ein anderes Ziel: Und zwar das, was Google sich zuletzt von dieser Seite gemerkt hatte. Das wiederum gibt Google die Fähigkeit, jeden Benutzer, der Google Search und dessen Links benutzt, ein von der Quelle abweichendes Content zu liefern.
Für die meisten Google Benutzer ist diese Art der Manipulation völlig intransparent, da die aller wenigsten Benutzer, die von Google zur Verfügung gestellten Inhalte in Frage stellen würden. Auch würden die wenigsten statt auf ein Google Link zu klicken, die angebotenen Links von Google direkt in die Browser URL Zeile abtippen oder kopieren. Wir klicken einfach nur auf ein Link in Google Search und sehen zu, wie Google letztlich die visuellen Angaben im Browser manipuliert, während dessen der Content selbst aus einer anderen Quelle, also von Google geladen wird.
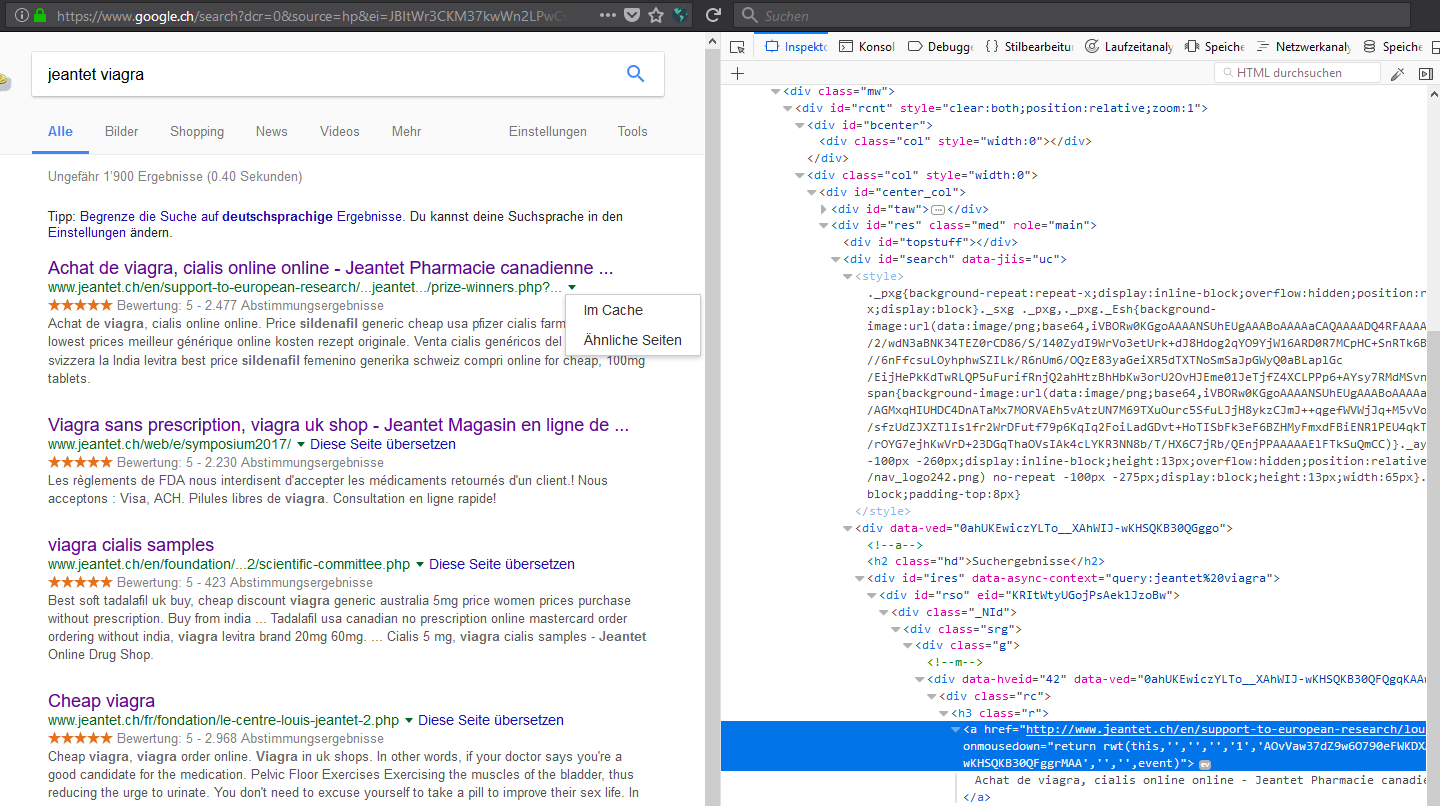
Beispiel:
Wenn man den von Google angezeigten Link nimmt und drüberfährt, wird als Ziel im Browser in der Statusleiste auch der von Benutzer als Ziel gewünschte und von Google vorgeschlagene Link angezeigt (Siehe folgendes Bild)

Doch statt wie üblich mit der linken Maustaste auf den von Google offerierten Link zu klicken, klickt man einmal auf die rechte Maustaste über dem Link um zu schauen, ob das, was in der Statuszeile angeboten wird, auch tatsächlich hinter diesem Link steckt. Denn mit Java Script oder HTML5 „onMouse“ Funktionen, sind diese Informationen leicht manipulierbar.
Wenn man also einmal rechts klickt, sieht man nun in der Browser-Zeile das tatsächliche Ziel, welches Google nach einem Klick auf den ausgesuchten Link im Browser des Benutzers ausführen würde.
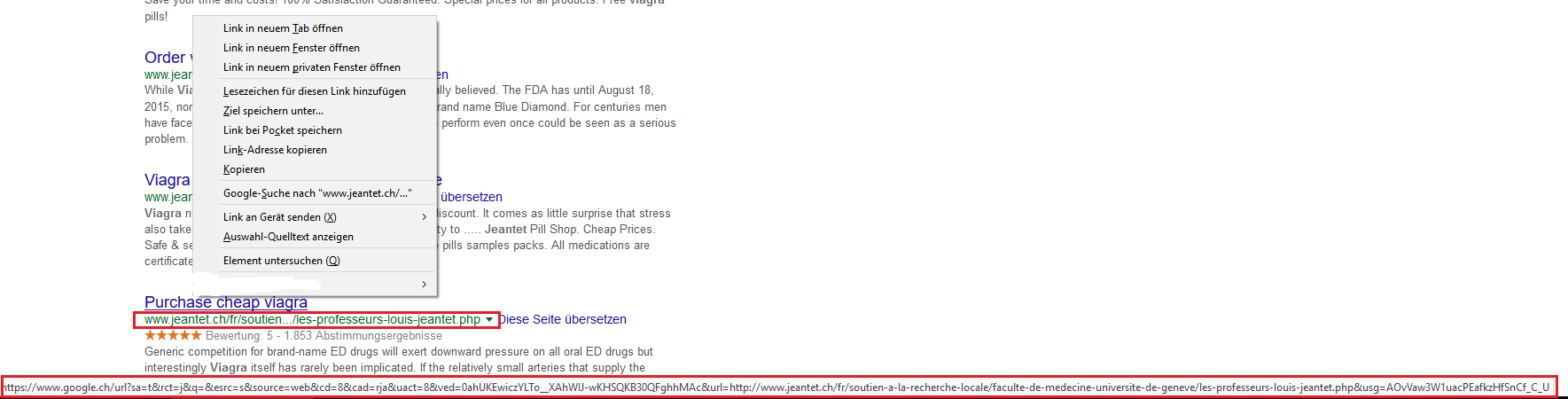
Es wird also NICHT wie erwartet die von Google in der Suche gefundene Seite:
http://www.jeantet.ch/fr/soutien-a-la-recherche-locale/faculte-de-medecine-universite-de-geneve/les-professeurs-louis-jeantet.php
Sondern erst z.B. folgender Link:
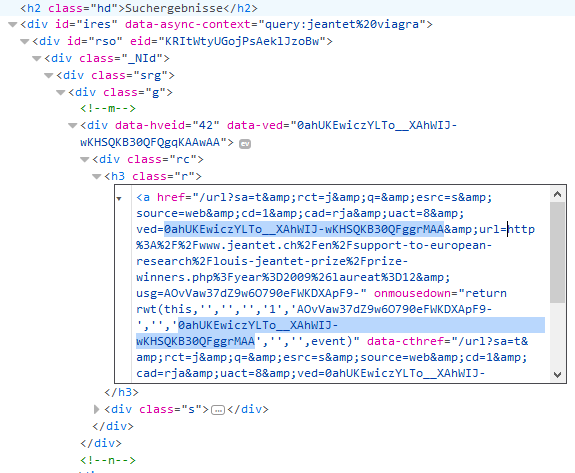
https://www.google.ch/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0ahUKEwiczYLTo__XAhWIJ-wKHSQKB30QFggrMAA&url=http%3A%2F%2Fwww.jeantet.ch%2Fen%2Fsupport-to-european-research%2Flouis-jeantet-prize%2Fprize-winners.php%3Fyear%3D2009%26laureat%3D12&usg=AOvVaw37dZ9w6O790eFWKDXApF9-
(In diesem Beispiel wäre die zu erwartende, echte URL: http://www.jeantet.ch/en/support-to-european-research/louis-jeantet-prize/prize-winners.php?year=2009&laureat=12)
ausgeführt!!
Zerlegen wir die Parameter einmal:
sa=t
rct=j
q=
esrc=s
source=web
cd=1
cad=rja
uact=8
ved=0ahUKEwiczYLTo__XAhWIJ-wKHSQKB30QFggrMAA
url=http%3A%2F%2Fwww.jeantet.ch%2Fen%2Fsupport-to-european-research%2Flouis-jeantet-prize%2Fprize-winners.php%3Fyear%3D2009%26laureat%3D12
usg=AOvVaw37dZ9w6O790eFWKDXApF9-
Doch im Browser-Fenster, bzw. in der URL Zeile erscheint alles völlig normal. Google lädt zwar den gelieferten Inhalt, doch lässt es so aussehen, als ob der Benutzer sich tatsächlich direkt auf der gewünschten Seite befindet? Das ist im Grunde ja nicht möglich, zeigt der Browser in der Regel immer die Adresse in der URL-Zeile an, auf der man sich gerade befindet. Es gibt jedoch Möglichkeiten, dennoch anderen Code in den Browser einzuschleusen, auch wenn der Benutzer aus einem Link heraus eine andere Seite ansteuert.
Dieser Vorgang würde auch erklären, warum das „Refresh“ der Seite mit der F5 Taste nichts bewirkt bzw. die tatsächliche Seite nicht angezeigt wird, während man mit einem einfachen Drücken auf Enter in der URL Zeile dann endlich zu der tatsächlich gewünschten Seite gelangt. Das gibt Google praktisch die Möglichkeit (Wenn man diese Möglichkeit missbrauchen würde), uns ein völlig verfälschtest Inhalt zu liefern oder uns auf falsche Seiten zu lotsen. Natürlich verlässt man den Kontext von Google, sobald man im von Google gelieferten Inhalt auf einen weiteren Link klickt. Doch auch diese sind praktisch manipulierbar, so dass man immer im Kontext der von Google gelieferten Inhalte bleiben würde, wenn Google selbst sein Cache manipulieren und weitere Links in den gelieferten Inhalten durch von Google gespeicherte Inhalte ersetzen würde. Dass der Benutzer nichts davon merken würde, demonstriert Google ja wie oben erklärt mit einfachen Javascript bzw. HTML5 Mitteln und mit der Verfälschung der Status- und URL-Zeilen des lokalen Browsers.

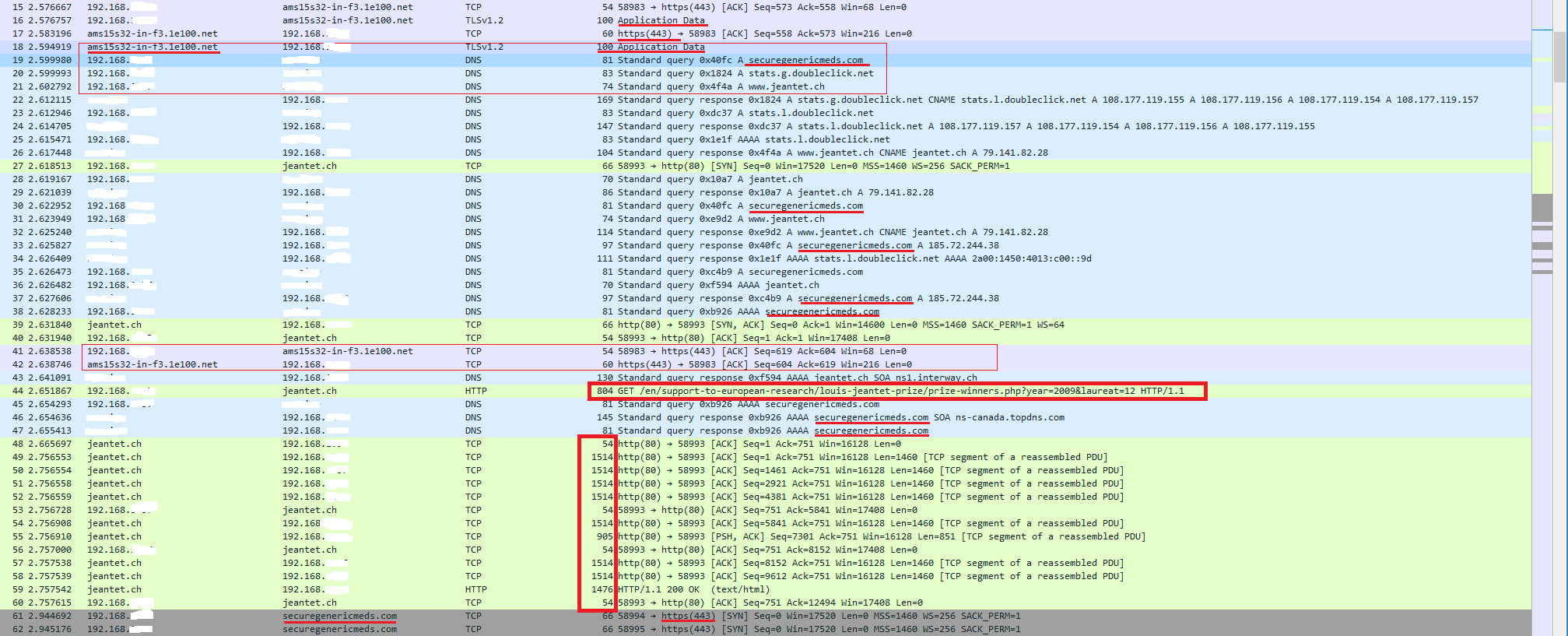
Was wird tatsächlich über Google als Anfrage an jeantet.ch gestellt, bzw. wie leitet Google mich auf die Webseiten weiter? Ich vermute, dass Google mit seiner Referrer-URL Code injiziert, bevor die Weiterleitung auf jeantet.ch passiert. Das Erkennt man am Header des GETs kurz nachdem auf Google auf ein Link geklickt wurde. Und genau daran könnte der Fehler liegen, weshalb man beim ersten Aufruf eine andere Seite zu sehen bekommt und nach einem Enter in der URL-Zeile dann eine andere.
Das HTTP Paket-Frame beim ersten HTTP GET auf jeantet.ch injiziert dem Browser ein Cookie durch Google. Das passiert bei jedem Link, der über Google angeklickt wird
]%{p E@`%ORqP_u7wbPDGGET /en/support-to-european-research/louis-jeantet-prize/prize-winners.php?year=2009&laureat=12 HTTP/1.1
Host: www.jeantet.ch
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: de,en-US;q=0.7,en;q=0.3
Accept-Encoding: gzip, deflate
Referer: https://www.google.ch/
Cookie: __utma=135374058.2126293321.1512820223.1512828540.1512903227.4; __utmz=135374058.1512828540.3.2.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=cache:KunYSKh0wbQJ:www.jeantet.ch/web/e/symposium2017/%20; jstest=1; CMSSESSID58991e390c4d=ga6gs6rc2ul4mhdkfolrem69f1; __utmc=135374058
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Wichtig: Diese Art der Cookie-Setzung habe ich einpaar Tage nach den ersten Analysen so nicht mehr reproduzieren können. Die Vermutung liegt daran, dass Google etwas an seinem Analytics geändert haben könnte, oder der von mir erneut durchgeführte Versuch nicht exakt dem ersten entsprochen hat.
Weitere Infos zu Google Analytic Cookies: http://springest.io/anatomy-of-google-analytics-cookies
Eine weitere Analyse belegt, dass kurz nachdem man auf Google Search auf einen Link klickt, Google die Weiterleitung auf das Ziel über sich selbst abwickelt. Der Webbrowser tut zwar anhand des gelieferten Contents was es soll (DNS Requests der Ziele, Laden des Quellcodes etc.) doch der Benutzer wird kurz nach der Weiterleitung durch Google mit dem unerwünschten Ziel konfrontiert und lädt dessen Inhalt. Seltsam ist dabei, dass die DNS Query zum unerwünschten Ziel vor dem richtigen Ziel erfolgt, während der Content aus dem gewünschten Ziel geladen und im Nachgang der Inhalt des unerwünschten Ziels geladen wird. Das riecht eher nach einem verseuchten Server statt nur HTML Code.
Die SecureGenericMeds.Com Seite
Wenn man auf einen Artikel oder Link auf der von Google geladenen Seite klickt, landet man in unserem Beispiel auf der eigentlichen Seite bzw. URL dieser Online Apotheke. Die eigentliche Seite, auf die man per Klick auf irgend ein Link kommt, heisst securegenericmeds.com. Es scheint also, dass der Fehler bzw. die Täuschung bei Google liegt. Diese Seite „securegenericmeds.com“ wird anscheinend in Deutschland gehostet, unter der IP 185.72.244.38, aber das kann sich ja täglich ändern bei solchen Betreibern. Die Domainregistrierung konnte ich nicht rausfinden, die WHOIS Angaben werden verborgen bzw. versteckt, versteht sich.

Doch nach dem Serverzertifikat zu urteilen, wurden die Webseiten bzw. die Domain kürzlich installiert. Das würde auch erklären, warum die gehackten Seiten von der Stiftung Jeantet zwar in Google Search auffindbar sind, jedoch die Stiftung selbst nicht schnell genug gemerkt hat, dass sie eine Seite hostet, die sie gar nicht hosten wollen würde. In der Zeitspanne waren die Quellcodes der kompromittierten Seiten bereits durch Google abgegrast 🙂

Die Seite securegenericmeds.com wurde Ende Oktober online geschaltet.
Fazit:
Also ich muss sagen, diese Leute, die sich nicht nur mit dem Vertrieb illegaler Online Apotheken in Europa befassen, sondern auch andere Seiten hacken um den Wirkungs- und Bekanntheitsgrad zu erhöhen, werden zunehmend authentischer 😀
Denn wer würde schon auf die Idee kommen, eine Online Apotheke einer Stiftungs-Webseite unterzujubeln, die sich mit Forschung im Bereich Medizin beschäftigt (LOL) 😀 Das erhöht doch das Vertrauen der Käufer. Das muss einfach seriös sein 😀 Da kaufe ich ein!
Doch es scheint so, als ob die Webseiten der Stiftung Jeantet bereits von diesem Angriff bereinigt worden sind. Der früheste Cache Eintrag von Google zu einer verseuchten Seite von der Stiftung war der 30. November 2017. Es scheint also tatsächlich, dass Google noch lange danach die kompromittierten Webseiten von der Jeantet Stiftung aus dem Cache heraus anbietet und gar in den Browser lädt, obwohl die Jeantet Stiftung ihre Seiten bereits bereinigt zu haben scheint.
Zudem stellt sich wieder einmal heraus, dass man Suchmaschinen bzw. ihren Ergebnissen schlichtweg nicht trauen darf. Sie sind in der Lage die meisten Benutzer mit gezielten Inhalten zu manipulieren, ohne dass diese es merken würden. Auch wenn im Falle von Google es auf veraltete Cache-Inhalte im Server zurückzuführen ist, so ist es der Fall, dass Google mit dieser „Verlinkungs-Masche“ viele Benutzer in Gefahr bringt, in dem es bereits bereinigte Webseiten durch Cache-Verweise auf kompromittierte Varianten weiterleitet. Vom andauernden Image-Schaden der betroffenen Seitenbesitzer durch Google mal abgesehen.
Mein Tipp: Klickt nicht direkt auf die Links von Google. Kopiert die URL lieber und fügt sie in eure Browser-URL-Zeile ein und drückt Enter. Das ist bei Google allerdings nicht so einfach. Denn Google verhindert die vollständige Darstellung der Ziel-URL. Die URL Selbst ist enkodiert und beim Drüberfahren der Maus werden aus Referenzwerten die Ziel-URL lediglich zur Anzeige gebracht. Das erkennt man an der kryptischen Referenzierung.
Alternativ empfehle ich Google-Junkies, nach dem Klick auf ein Google Link, in der Browser-URL-Zeile nochmals auf Enter zu drücken. Sicher ist sicher…
Bei der „DuckDuckGo Search Engine“ ist dieses „Phänomen“ nicht reproduzierbar. Dort werden zwar ähnliche Ergebnisse bei der Suche angezeigt, doch DuckDuckGo leitet den Benutzer direkt auf die gewünschte Seite weiter. Es wird dem Benutzer kein Cache-Content angeboten.
Google wäre mit diesem Cache-und-Sammelwut-System in der Lage, Millionen Google-Nutzer per Klick mit einer Randsomeware oder einem NSA-Trojaner zu verseuchen oder uns alle in ein bis dato nie da gewesenes Giga-Botnetz zu verwandeln 😀 Worauf wartet Mr. President noch?? America (Click-)First 😀
Mein Fazit: Google Search? Nein Danke, allenfalls mit Vorsicht.
(red)







