
(Inhalt editiert am 17.12.2017)
Um dem Titel dieses Artikels gerecht zu werden, müsste Google etwas entdeckt oder über etwas Forschung betrieben haben, was der Menschheit wissenschaftlich gesehen grosse Erkenntnisse und Fortschritt gebracht hätte, oder je nachdem auch in falschen Händen auch eine enorme Zerstörungskraft besitzen würde.
Mit Hilfe meiner bescheidenen Intelligenz versuche ich einmal mit meinen einfachen Erkenntnissen eine These aufzustellen und überlasse die Beurteilung über Sinn und Unsinn den Leserinnen und Lesern. Ich werde nie so schlau sein wie z.B. ein Oppenheimer oder vergleichbare Wissenschaftler, geschweige denn ein Google-aner werden (man soll ja niemals nie sagen, also was Google betrifft). Wobei man sich ja darüber streiten kann, was an so manchen Erkenntnissen der Menschheit tatsächlich schlau ist oder war.
Zweifelsohne hat Google seit seiner Entstehung unser Leben in irgend einer Art und Weise beeinflusst, ob es nun die Suchmaschine ist, womit alles begann, oder mit vielen weiteren Dienstleistungen, die im Laufe der Zeit unter dem Dach des heute riesigen Unternehmens entstanden sind (Wenn ich alleine an Youtube denke 🙂 wobei YT von Google zugekauft wurde). Und natürlich forscht auch Google wie ein Weltmeister in fast allen Gebieten der Mathematik, Physik, Chemie, künstliche Intelligenz, selbstfahrende Autos, intelligente Sprachassistenten etc. Ich würde mich nicht wundern, wenn es bald auch “Google-Coins”, “Google Bank”, “Google Super Market” etc. geben würde. Also “Google Sachs” würde doch gut passen, statt “Goldman Sachs”, oder “G Corp” statt “E Corp” aus der US-amerikanischen Serie Mr. Robot. Eins weiss ich, Google wird seine Shops niemals “G Point” nennen. OK, genug rumgealbert.
Wenn die Statistiken von Statista.com verlässlich sind, nutzen mindestens 1.17 Milliarden Menschen Google (Stand 2012!). Bedenkt man, dass gerade mal ca. die Hälfte der Menschheit an das Internet angeschlossen ist, ergibt dies ca. 1/3 aller Internetanwender.

(Quelle: https://de.statista.com/infografik/895/anzahl-der-eindeutigen-sucher-weltweit/)
Dazu überholte der Chrome Browser von Google die Konkurrenten in der Anzahl von genutzten Instanzen mit einem beachtlichen Abstand (Stand Januar 2017)

(Quelle: https://de.statista.com/infografik/427/globale-marktanteile-webbrowser/)
Wenn wir also aus den beiden Ergebnissen eine kombinierte Auswertung machen wollten, würden rund 63% aller Internetanwender die Seiten von Google mit dem Chrome Browser ansteuern (In der Annahme, dass alle Internetanwender einmal Google.com/de/ch etc. besuchen würden). Das ergibt ca. 700 Mio. Chrome-Google Kombinationen. Beachtlich. Diese Zahlen sind lediglich Variationen, denn jeder Internetbenutzer wird wahrscheinlich einmal mit Google oder dessen Browser, oder gar beides in Berührung kommen. Die Tatsache, dass Chrome nach dessen Installation und erster Ausführung die Google Search Engine ansteuert (logischer Weise die Standardsuchmaschine) und die meisten Benutzer in der Regel die Suchmaschine zumindest am Anfang beibehält, macht das ganze zu einer explosiven Mischung, die nicht zwangsläufig hochgehen muss, aber könnte, ja also theoretisch, wenn man wollte.
Das Potenzial liegt bei Google, begünstigt durch unsere Gewohnheiten, Googles Bemühungen den Nutzer an sich zu binden, seine feste Verankerung in diversen Software- und Hardwareprodukten etc.. Lange Rede kurzer Sinn: Wir sind doch fast alle irgendwie Google verseucht. Das man dies in zweierlei Hinsicht verstehen muss, werde ich in diesem Beitrag versuchen näher zu bringen.
Nun, eine weitere Tatsache, dass Google anscheinend in der Lage ist, jegliche, von Google erreichbaren Internetseiten vollständig zu speichern und als Cache-Inhalt anzubieten, ja gar per Klick auf ein Google-Search Link in den Browser zu laden, könnte etwas nützliches, vielfach benutztes in etwas anderes umwandeln. Mittlerweile ist Google sogar in den meisten Köpfen fester Bestandteil im Wortschatz geworden. Man fragt Google, man googlet, etc. Wie soll denn bitte sehr Google zu einer Waffe werden, das ist doch so ein Schwachsinn gepaart mit Verschwörungstheorien? Nun ja, manche Menschen meinen, das Messer ist ein Werkzeug, andere nutzen es als Waffe. So manche für beide Zwecke.
Warum also soll ein mächtiger Konzern wie Google, der unser Leben mit sovielen kostenlosen Diensten wie Google Search, Google Maps, Google Translator etc. vereinfacht, für uns zugleich eine Gefahr darstellen? Der Grund liegt nicht in der Absicht, sondern im Potenzial. Und wenn wir über Potenzial nachdenken, werden wir feststellen, dass im Laufe der Weltgeschichte so einiges Potential irgendwann zweckentfremdet gegen einem genutzt wurde, aus welchen Gründen auch immer.
Beschränkt man sich lediglich auf das Gefahrenpotenzial, welches allein Google Search mit sich bringt, sollten aus meiner Sicht folgende Risiken nicht ausser Acht gelassen werden. Die meisten Menschen glaubten und glauben nicht daran, dass so manche “Hirngespinste” einiger weniger Menschen sich irgendwann bewahrheiten könnten. In der heutigen Welt gilt für mich daher “Erwarte das unerwartete!”
Technisch gesehen hat sich Google mit seinem Google Search eine exklusive Möglichkeit geschaffen,
A. das gesamte WWW (soweit von Google erreichbar) zu kopieren,
B. das gesamte WWW historisch zu katalogisieren,
C. allen Benutzern, die Google Search benutzen einen von der Quelle abweichenden und/oder veränderten Inhalt zu liefern,
D. in Kombination mit Google Chrome potenziell gesehen sich auf jedem System eine Hintertür zu öffnen, egal wie gut ein System gepatched ist oder mit einer Antivirussoftware geschützt,
E. pratisch jedem Benutzer beliebige Werbung aufzuzwingen oder über ihn ein Profil zu erstellen, ob er nun bei Google ist oder nicht,
F. jeden beliebigen PC bei Besuch mit Schadcode zu infizieren,
G. jeden beliebigen PC in ein BOT zu verwandeln, somit das grösste, nie da gewesene Bot-Netz zu schaffen.
Die Fakten anhand eines Suchbeispiels auf google.com
Letztlich wurden die Fakten hierzu in meinem vorherigen Beitrag über die Webseiten der Louis Jeantet Stiftung ausführlich genannt. Dennoch möchte ich den Sachverhalt hier nochmals erläutern. Bei einem Besuch der Google Search Seite (Es spielt keine Rolle ob .COM, .DE, .CH etc.) und der Suche nach einem Begriff bekommt man von Google die entsprechenden Ergebnisse angezeigt. Man ist als Benutzer ja erst einmal auf der Google Seite gelandet.
(Um das nachfolgende Szenario vollständig nachvollziehen zu können, empfehle ich den vorherigen Beitrag durchzulesen)
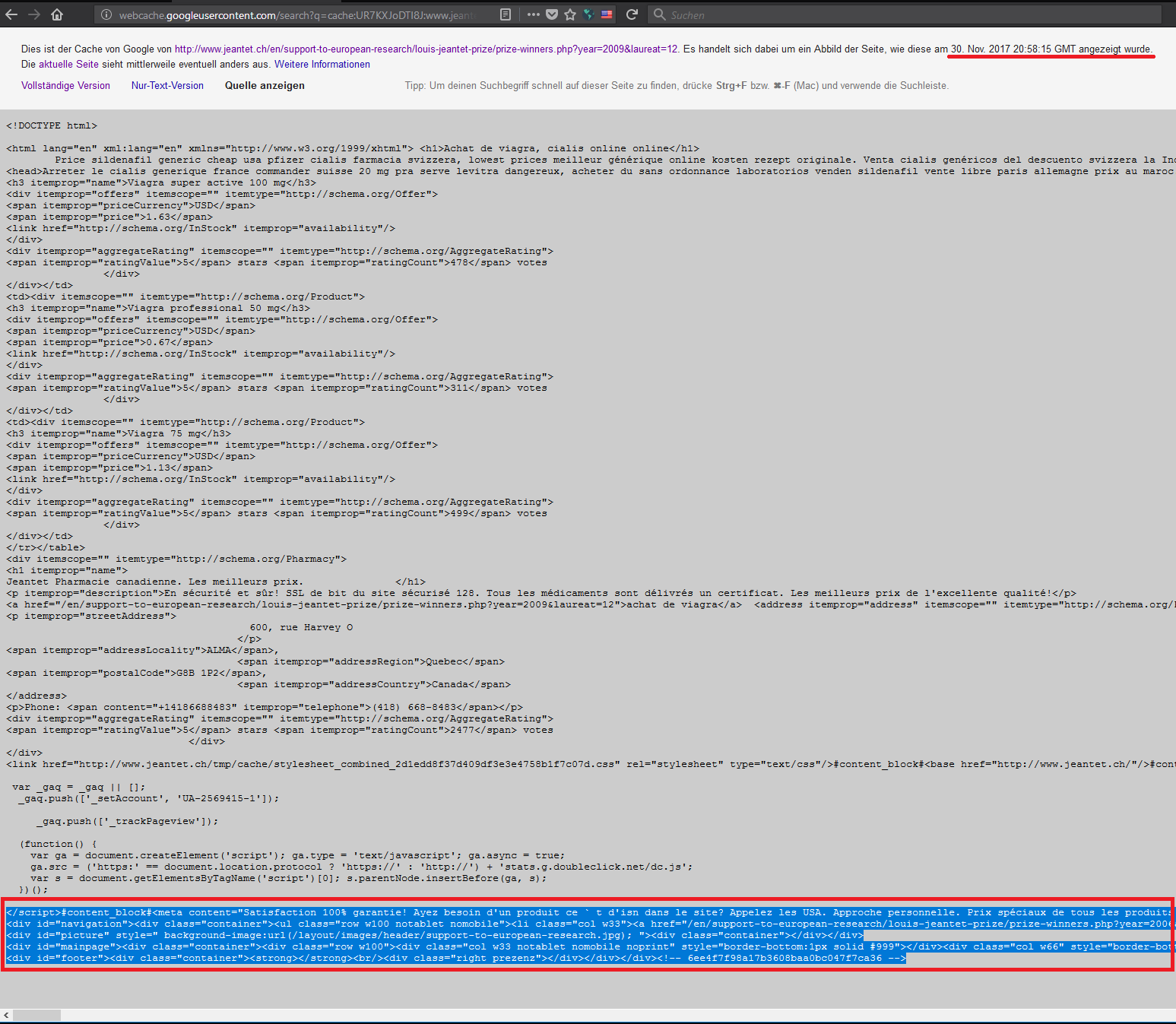
Im Rahmen der Recherchen über eine Stiftung, ging ich wie viele andere auch auf die Seite von Google Search und gab den entsprechenden Suchbegriff, in diesem Fall den Namen der Stiftung ein und lies mir die Ergebnisse anzeigen. Nachdem ich eines der Ergebnisse anklickte, landete ich auch gleich auf der gewünschten Seite. Doch der Inhalt, der mir auf der Seite angeboten wurde, war sehr kurios. Es ging dabei um eine Stiftung, die im Bereich der Biomedizin forscht. Doch obwohl ich laut den Browser-Angaben (ich benutzte Firefox) auf der richtigen Internetadresse zu sein schien, bekam ich eine Seite zu sehen, die alles andere als passend war, für eine Stiftung (die im Bereich der Biomedizin forscht). Es war eine illegale Online Apotheke für Potenz- und Aufputschmittel. Rufte man die URL manuell im Browser auf, erscheinte alles völlig normal:
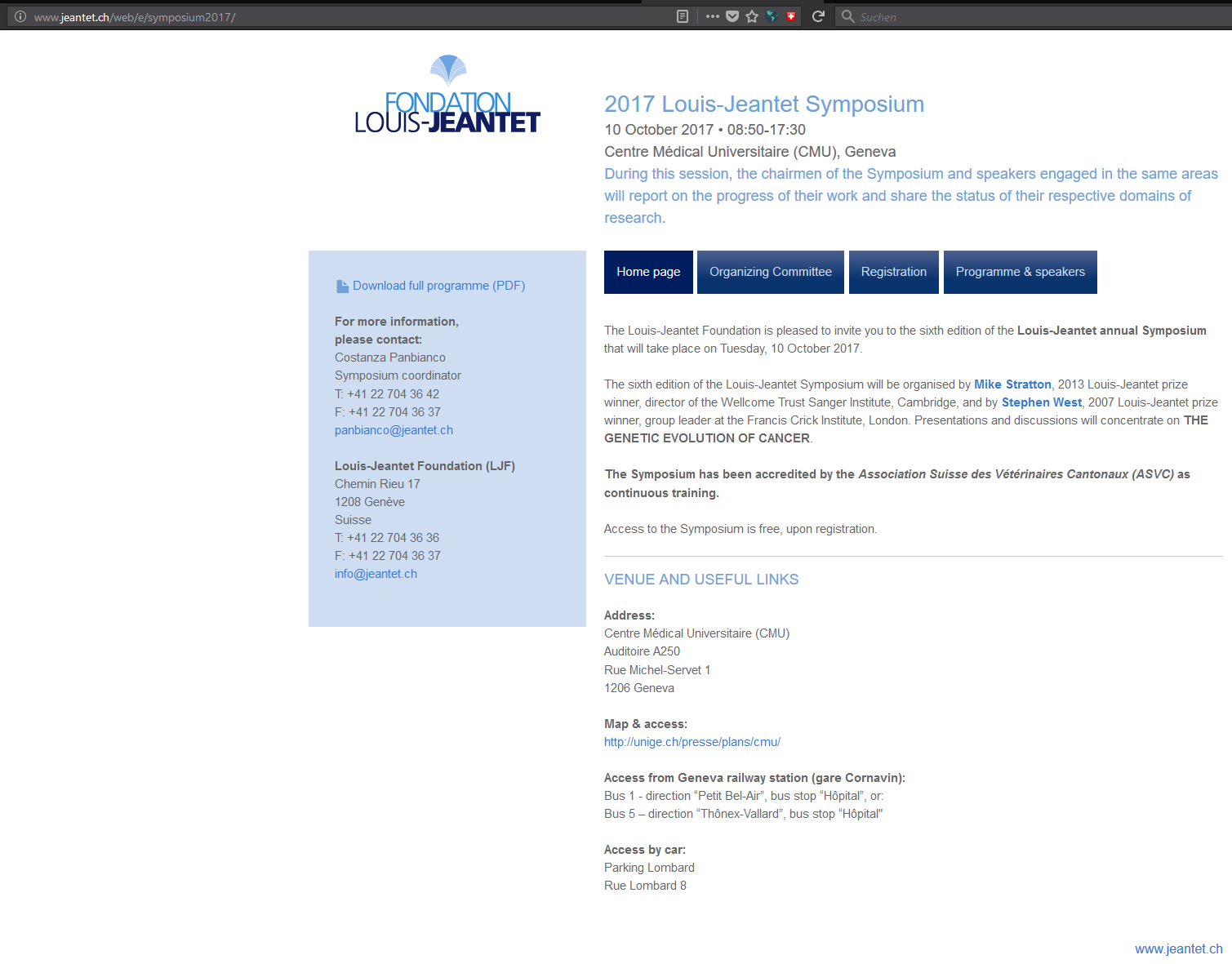
Doch nutzte man die GOOGLE Suche, dann wurde man beim ersten Aufruf der URL mit der Seite der illegalen Online Apotheke konfrontiert, bzw. die Seiten der Online Apotheke wurden geladen. Das war auch im Link von Google ersichtlich. Im Titel sah man die Angaben über die Apotheke, im Text wiederum die Meta-Daten der Stiftungs-Webseite.
BEISPIEL: Google Suche nach “JEANTET VIAGRA”
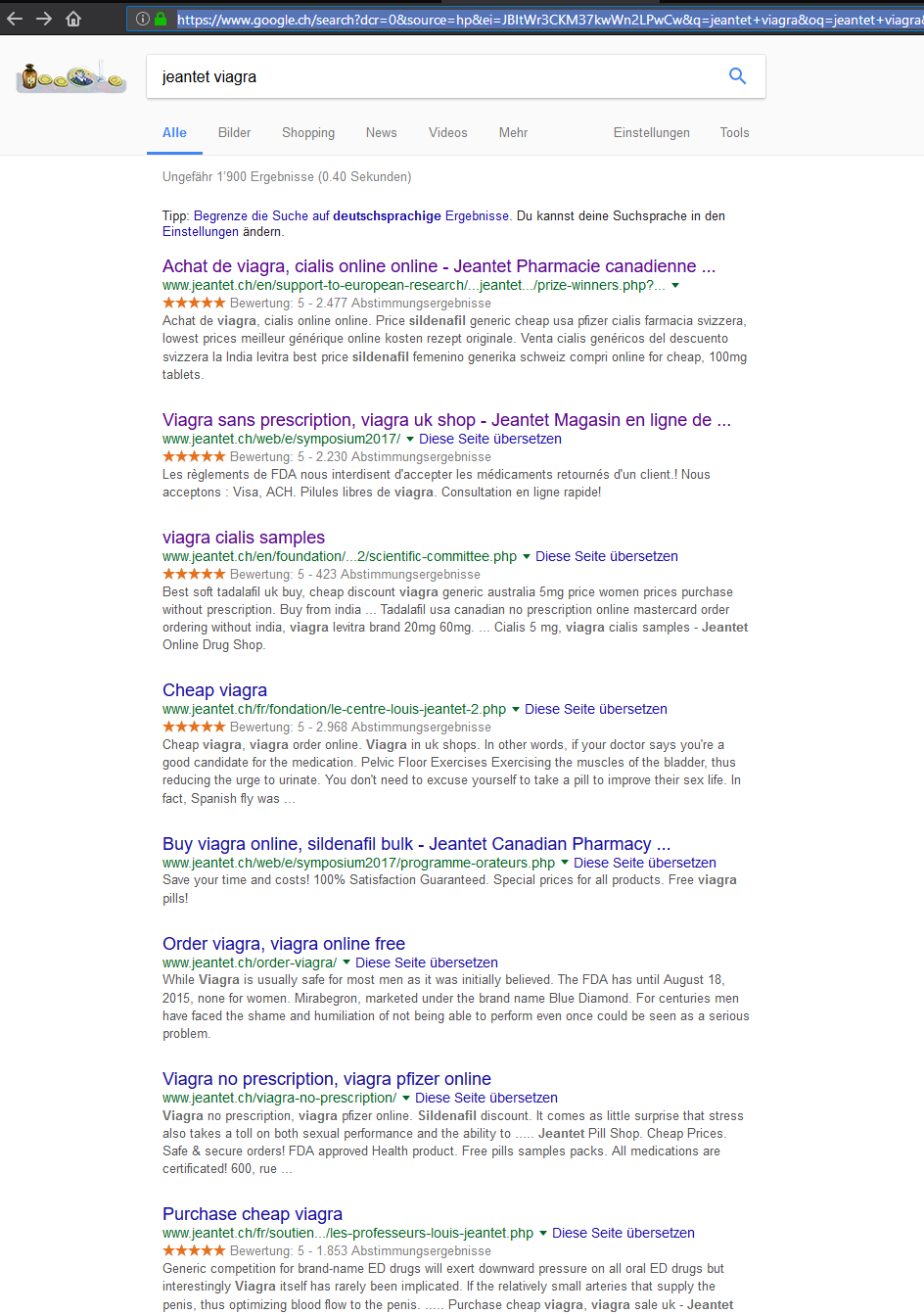
Nach einem Blick von Google Cache wurde das ganze etwas klarer.
- Die Cache Informationen des ausgewählten Links waren noch vom 6.12.2017.
- Die manipulierte Verlinkung habe ich jedoch erst am 9.12.2017 entdeckt.
Demnach musste die Seite der Stiftung tatsächlich zuvor infiziert worden sein, jedoch der Vorfall in der Zwischenzeit behoben, während Google aus dem Cache die Seite geladen hat(?), die zum Zeitpunkt der Manipulation seitens Google “ge-crawled” (ausgelesen) wurde? Das sollte nicht möglich sein, denn ich bin ja laut meinem Browser auf dem einen und gleichen Zielsystem, wenn ich die Seiten aufrufe.
Eine weitere Vermutung war es in einem ersten Verdachtsmoment, dass der Webmaster der Webseite nach der Bereinigung der Seiten (mit dem Code von der Online Apotheke nach dem Hack) den Cache der eigenen Content Management Software der Webseite nicht gelöscht hatte, somit beim ersten Aufruf über Google, der Webserver der Webseite die noch verseuchte Seite geladen hatte, beim Aktualisieren dann die tatsächlich gültige, bereinigte Seite aus dem Web-Space des Servers. Das ergab zwar keinen Sinn, aber ich weiss ja nicht, wie diese CMS Software auf dem Server funktioniert. Also nahm ich an, es liegt an der Seite, die ich besuchte.
Doch wenn die URL über Google aufgerufen wurde, half die Browser-Aktualisierung nichts, um die echte Stiftungs-Webseite, z.B. unter http://www.jeantet.ch/web/e/symposium2017/ zu bekommen.
Man konnte also aktualisieren wie man wollte, solange die URL selbst nicht manuell aufgerufen wurde, blieb die Apothekenseite unter der gleichen URL-Zeile bestehen. Es macht nämlich ein Unterschied, ob man im Nachgang in der URL Zeile erneut auf Enter drückt (also die Seite aufruft), oder mit Strg+F5 den Browser-Cache aktualisiert (also den geladenen Quellcode erneut lädt). Im letzteren Fall bleibt die aufgebaute, in meinem Browser anscheinend kompromittierte Seite, welche ich per Google Search aufrufe, erhalten. Per Enter in der URL Zeile bekomme ich dann endlich die richtige Seite nachgeladen.
Woran könnte das liegen und was passiert wirklich bei einem Klick?
Das liegt nicht etwa daran, dass es in meinem Browser spukt es ein unterschied wäre, ob ich beim Besuch auf eine Seite in der URL Zeile auf Enter drücke oder auf F5.
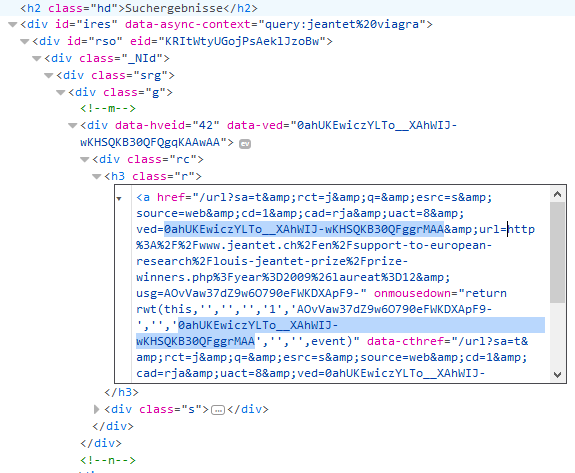
Es könnte daran liegen, dass Google dem Google-User was “vormacht”, wenn der User eine Seite über Google besucht. Wenn man bei Google Search mit der Maus auf einen Link fährt, dann bekommt man in der Statuszeile des eigenen Browsers den von Google gefundenen Link angezeigt, auf den man “normaler Weise” dann auch gehen würde, wenn der Link angeklickt wird. Tatsächlich hinterlegt Google jedoch in der Linkzeile ein anderes Ziel: Und zwar das, was Google sich zuletzt von dieser Seite gemerkt hatte. Das wiederum gibt Google die Fähigkeit, jeden Benutzer, der Google Search und dessen Links benutzt, ein von der Quelle abweichendes Content zu liefern.
Für die meisten Google Benutzer ist diese Art der Manipulation völlig intransparent, da die aller wenigsten Benutzer, die von Google zur Verfügung gestellten Inhalte in Frage stellen würden. Auch würden die wenigsten statt auf ein Google Link zu klicken, die angebotenen Links von Google direkt in die Browser URL Zeile abtippen oder kopieren. Wir klicken einfach nur auf ein Link in Google Search und sehen zu, wie Google letztlich die visuellen Angaben im Browser manipuliert, während dessen der Content selbst aus einer anderen Quelle, also von Google geladen wird.
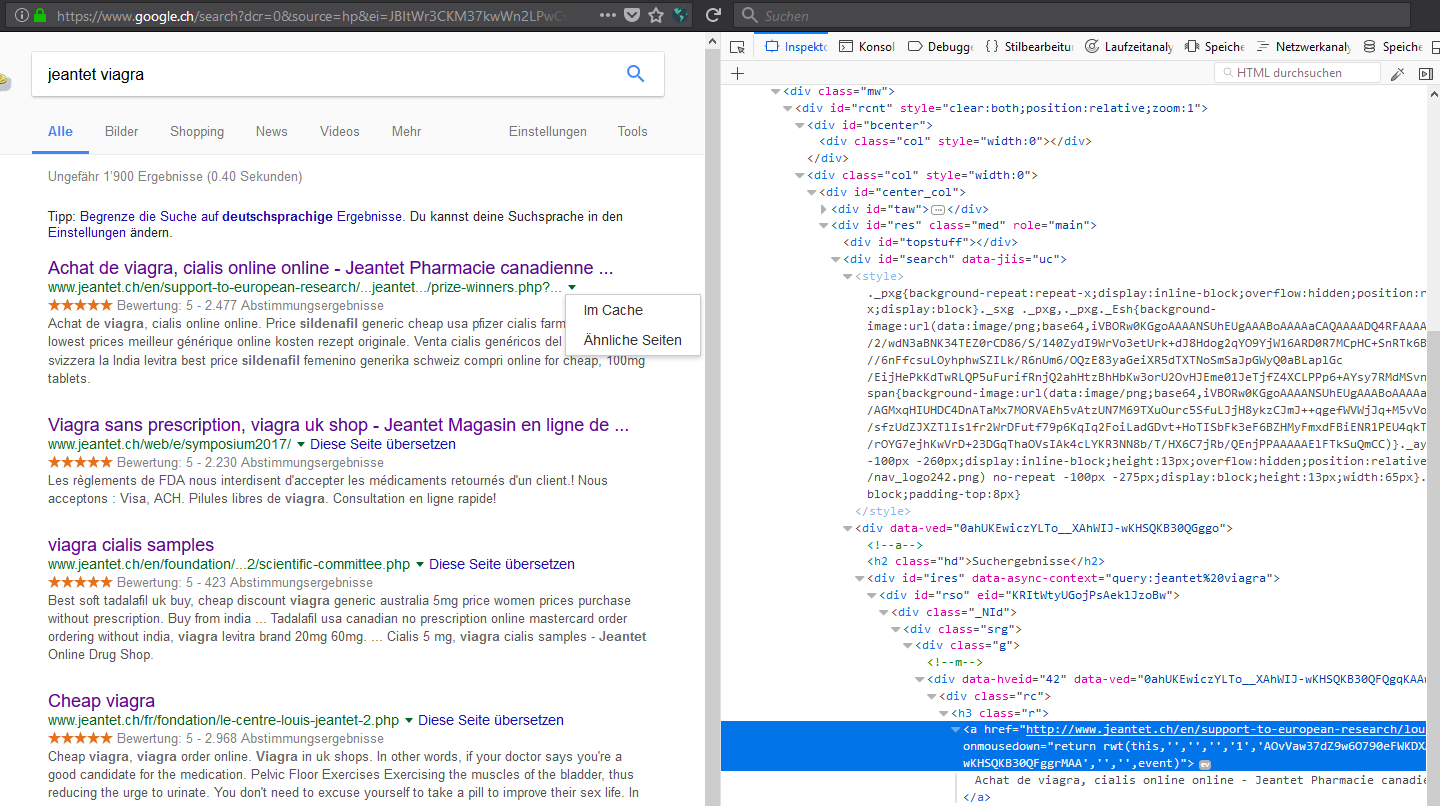
Beispiel:
Wenn man den von Google angezeigten Link nimmt und drüberfährt, wird als Ziel im Browser in der Statusleiste auch der von Benutzer als Ziel gewünschte und von Google vorgeschlagene Link angezeigt (Siehe folgendes Bild)

Doch statt wie üblich mit der linken Maustaste auf den von Google offerierten Link zu klicken, klickt man einmal auf die rechte Maustaste über dem Link um zu schauen, ob das, was in der Statuszeile angeboten wird, auch tatsächlich hinter diesem Link steckt. Denn mit Java Script oder HTML5 “onMouse” Funktionen, sind diese Informationen leicht manipulierbar.
Wenn man also einmal rechts klickt, sieht man nun in der Browser-Zeile das tatsächliche Ziel, welches Google nach einem Klick auf den ausgesuchten Link im Browser des Benutzers ausführen würde.
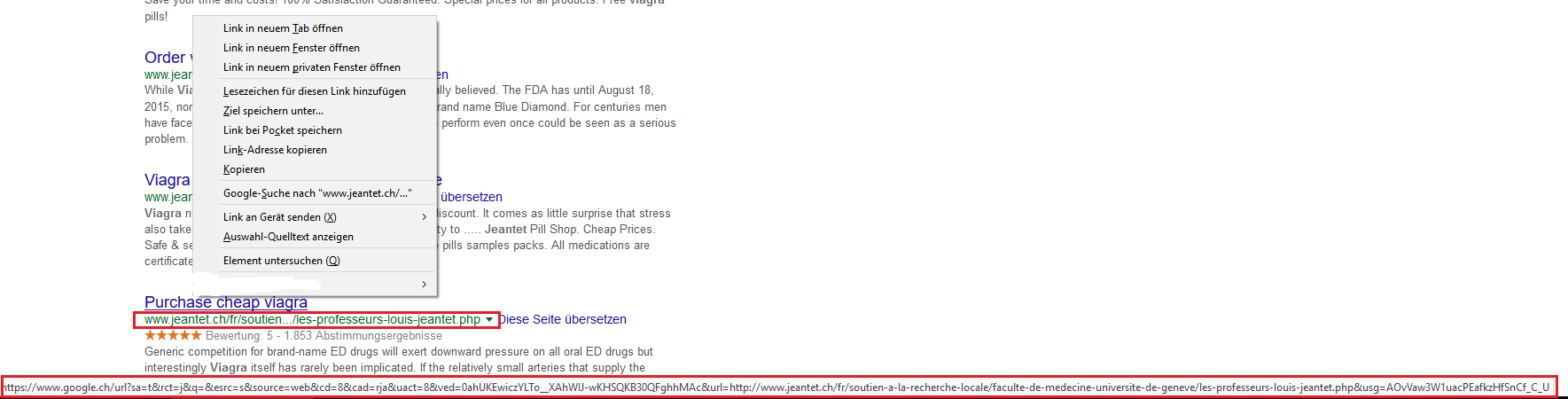
Es wird also NICHT wie erwartet die von Google in der Suche gefundene Seite:
http://www.jeantet.ch/fr/soutien-a-la-recherche-locale/faculte-de-medecine-universite-de-geneve/les-professeurs-louis-jeantet.php
Sondern erst z.B. folgender Link:
https://www.google.ch/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0ahUKEwiczYLTo__XAhWIJ-wKHSQKB30QFggrMAA&url=http%3A%2F%2Fwww.jeantet.ch%2Fen%2Fsupport-to-european-research%2Flouis-jeantet-prize%2Fprize-winners.php%3Fyear%3D2009%26laureat%3D12&usg=AOvVaw37dZ9w6O790eFWKDXApF9-
(In diesem Beispiel wäre die zu erwartende, echte URL: http://www.jeantet.ch/en/support-to-european-research/louis-jeantet-prize/prize-winners.php?year=2009&laureat=12)
ausgeführt!!
Zerlegen wir die Parameter einmal:
sa=t
rct=j
q=
esrc=s
source=web
cd=1
cad=rja
uact=8
ved=0ahUKEwiczYLTo__XAhWIJ-wKHSQKB30QFggrMAA
url=http%3A%2F%2Fwww.jeantet.ch%2Fen%2Fsupport-to-european-research%2Flouis-jeantet-prize%2Fprize-winners.php%3Fyear%3D2009%26laureat%3D12
usg=AOvVaw37dZ9w6O790eFWKDXApF9-
Doch im Browser-Fenster, bzw. in der URL Zeile erscheint alles völlig normal. Google lädt zwar den gelieferten Inhalt, doch lässt es so aussehen, als ob der Benutzer sich tatsächlich direkt auf der gewünschten Seite befindet? Das ist im Grunde ja nicht möglich, zeigt der Browser in der Regel immer die Adresse in der URL-Zeile an, auf der man sich gerade befindet. Es gibt jedoch Möglichkeiten, dennoch anderen Code in den Browser einzuschleusen, auch wenn der Benutzer aus einem Link heraus eine andere Seite ansteuert. Die einfachste Variante sind sogenannte I-Frames. Andere Varianten wären Display Overlays oder Code-Embedding/Injection
Dieser Vorgang würde auch erklären, warum das “Refresh” der Seite mit der F5 Taste nichts bewirkt bzw. die tatsächliche Seite nicht angezeigt wird, während man mit einem einfachen Drücken auf Enter in der URL Zeile dann endlich zu der tatsächlich gewünschten Seite gelangt. Das gibt Google praktisch die Möglichkeit (Wenn man diese Möglichkeit missbrauchen würde), uns ein völlig verfälschtest Inhalt zu liefern oder uns auf falsche Seiten zu lotsen. Natürlich verlässt man den Kontext von Google, sobald man im von Google gelieferten Inhalt auf einen weiteren Link klickt. Doch auch diese sind praktisch manipulierbar, so dass man immer im Kontext der von Google gelieferten Inhalte bleiben würde, wenn Google selbst sein Cache manipulieren und weitere Links in den gelieferten Inhalten durch von Google gespeicherte Inhalte ersetzen würde. Dass der Benutzer nichts davon merken würde, demonstriert Google ja wie oben erklärt mit einfachen Javascript bzw. HTML5 Mitteln und mit der Verfälschung der Status- und URL-Zeilen des lokalen Browsers.

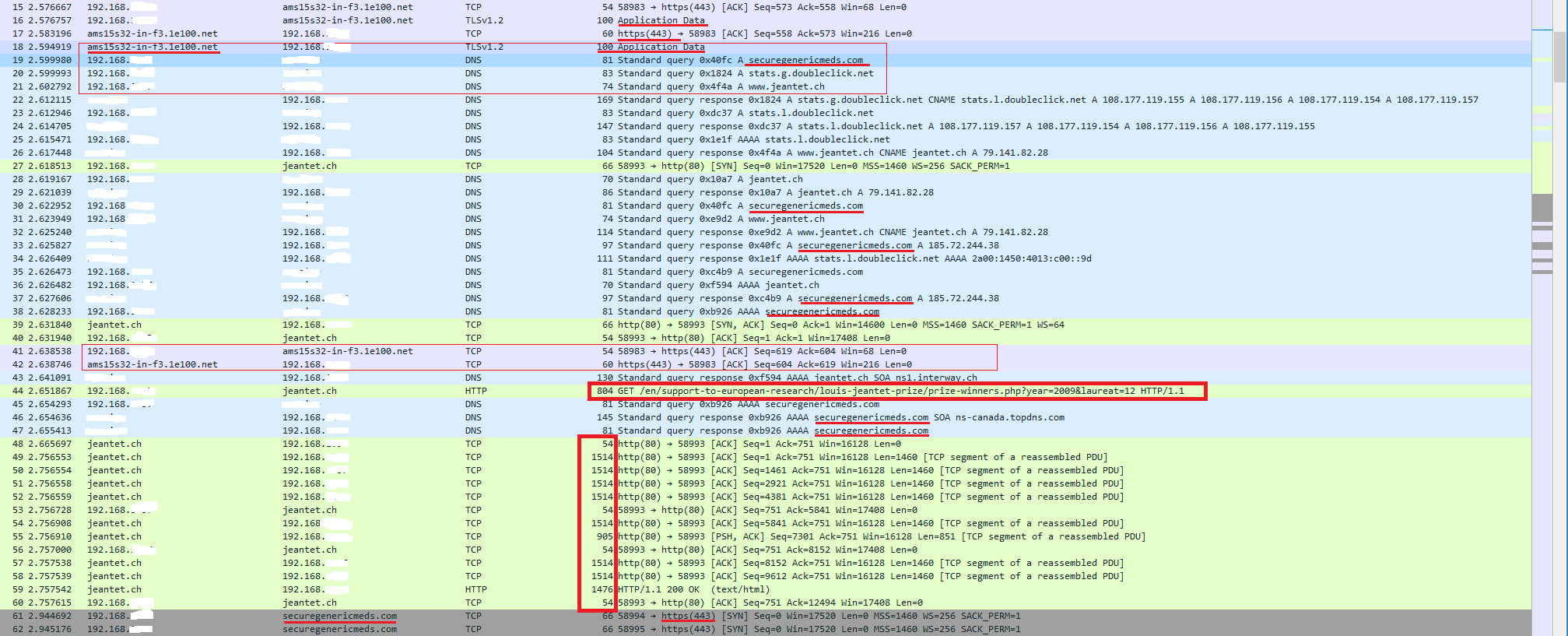
Eine weitere Analyse belegt, dass kurz nachdem man auf Google Search auf einen Link klickt, Google die Weiterleitung auf das Ziel über sich selbst abwickelt. Der Webbrowser tut zwar anhand des gelieferten Contents was es soll (DNS Requests der Ziele, Laden des Quellcodes etc.) doch der Benutzer wird kurz nach der Weiterleitung durch Google mit dem unerwünschten Ziel konfrontiert und lädt dessen Inhalt. Seltsam ist dabei, dass die DNS Query zum unerwünschten Ziel vor dem richtigen Ziel erfolgt, während der Content aus dem gewünschten Ziel geladen und im Nachgang der Inhalt des unerwünschten Ziels geladen wird. Das riecht eher nach einem verseuchten Server statt HTML Code.
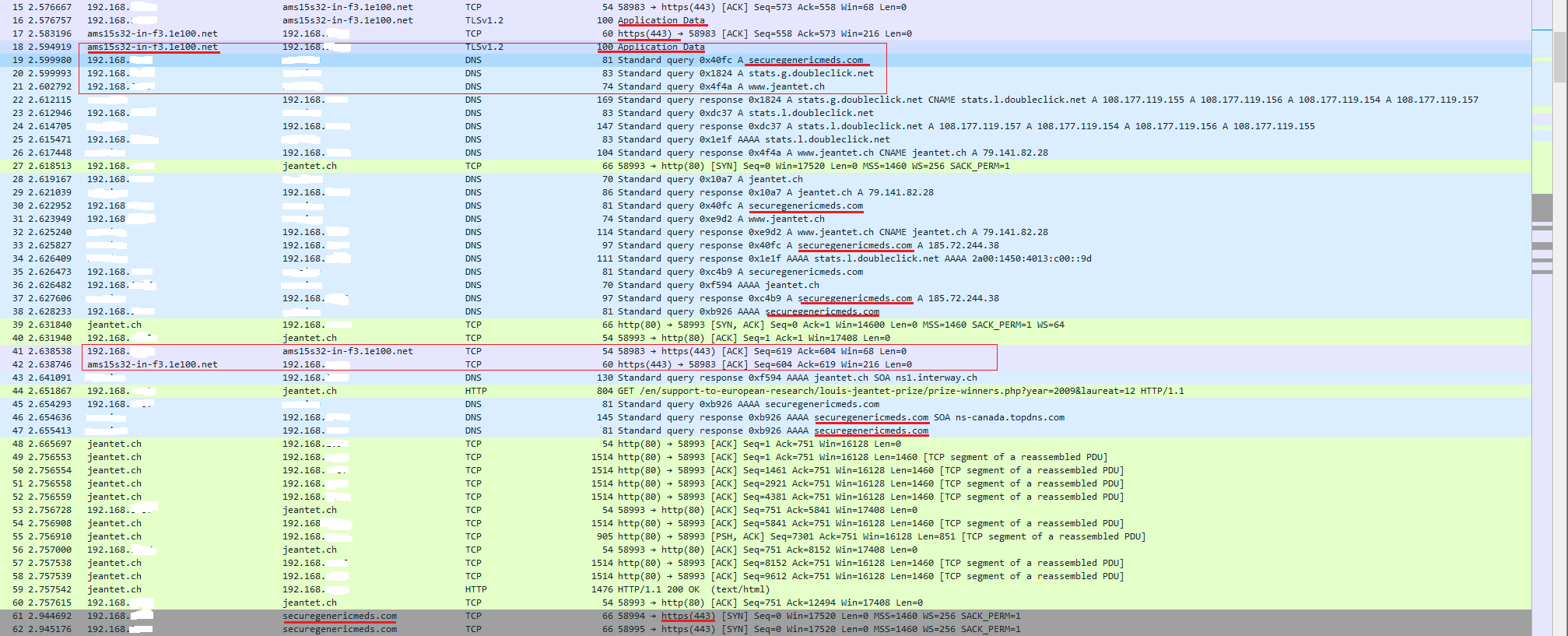
Was wird tatsächlich über Google als Anfrage an jeantet.ch gestellt, bzw. wie leitet Google mich auf die Webseiten weiter? Ich vermute, dass Google mit seiner Referrer-URL Code injiziert, bevor die Weiterleitung auf jeantet.ch passiert. Das Erkennt man am Header des GETs kurz nachdem auf Google auf ein Link geklickt wurde. Und genau daran könnte der Fehler liegen, weshalb man beim ersten Aufruf eine andere Seite zu sehen bekommt und nach einem Enter in der URL-Zeile dann eine andere.
Das HTTP Paket-Frame beim ersten HTTP GET auf jeantet.ch injiziert dem Browser ein Cookie durch Google. Das passiert bei jedem Link, der über Google angeklickt wird (Google Analytics Cookies)
]%{p E@`%ORqP_u7wbPDGGET /en/support-to-european-research/louis-jeantet-prize/prize-winners.php?year=2009&laureat=12 HTTP/1.1
Host: www.jeantet.ch
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: de,en-US;q=0.7,en;q=0.3
Accept-Encoding: gzip, deflate
Referer: https://www.google.ch/
Cookie: __utma=135374058.2126293321.1512820223.1512828540.1512903227.4; __utmz=135374058.1512828540.3.2.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=cache:KunYSKh0wbQJ:www.jeantet.ch/web/e/symposium2017/%20; jstest=1; CMSSESSID58991e390c4d=ga6gs6rc2ul4mhdkfolrem69f1; __utmc=135374058
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Wichtig: Diese Art der Cookie-Setzung habe ich einpaar Tage nach den ersten Analysen so nicht mehr reproduzieren können. Die Vermutung liegt daran, dass Google etwas an seinem Analytics geändert haben könnte, oder der von mir erneut durchgeführte Versuch nicht exakt dem ersten entsprochen hat.
Weitere Infos zu Google Analytic Cookies: http://springest.io/anatomy-of-google-analytics-cookies
Ergebnis/ mein Fazit
Es scheint tatsächlich so, als ob die Webseiten der Stiftung Jeantet bereits länger von diesem Angriff bereinigt worden sind. Der früheste Cache Eintrag von Google zu einer verseuchten Seite von der Stiftung war bei meinen Stichproben zwischen dem 24. und 30. November 2017. Es ist also wahr, dass Google noch lange danach die kompromittierten Webseiten von der Jeantet Stiftung dem Benutzer samt des zuvor gesammelten Quellcodes über eine Cache-Referenz anbietet und der Code per Klick und Cookie gar in den Browser geladen wird, obwohl die Jeantet Stiftung ihren gültigen Code bereits bereinigt zu haben scheint. Natürlich werden Daten wie Bilder oder ggf. andere Medien aus den im Code hinterlegten Adressen geladen, aber es ist einfach diese ebenfalls aus eigenen Quellen anzubieten, da Google praktisch alles speichert, nicht nur HTML Code.
Zudem stellt sich heraus, dass man Suchmaschinen bzw. ihren Ergebnissen schlichtweg nicht trauen darf. Sie sind in der Lage die meisten Benutzer mit gezielten Inhalten zu manipulieren, ohne dass diese es merken würden. Auch wenn im Falle von Google es auf veraltete Cache-Referenzen zurückzuführen ist, so ist es der Fall, dass Google mit dieser “Verlinkungs-Und-Cookie-Masche” viele Benutzer in Gefahr bringt, in dem es bereits bereinigte Webseiten mit ihren kompromittierten Varianten weiterhin zur Verfügung stellen könnte. Vom andauernden Image-Schaden der betroffenen Seitenbesitzer durch Google mal abgesehen.
Bei der DuckDuckGo Search Engine passiert einem das nicht. Dort werden zwar ähnliche Ergebnisse angezeigt, doch DuckDuckGo leitet den Benutzer direkt auf die gewünschte Seite weiter. Es wird dem Benutzer kein Cache-Content per Referenz geliefert.
Google wäre mit diesem Cache-System in der Lage, Millionen Google-Nutzer per Klick mit einer Randsomeware oder einem NSA-Trojaner zu verseuchen oder uns alle in ein bis dato nie da gewesenes Giga-Botnetz zu verwandeln. Denn wie gesagt, gerade weil ja auch Chrome von Google kommt, wäre es sehr leicht, nicht nur gefährlichen Code in die Rechner oder Android Tablets/Phones der Benutzer zu laden, sondern über eine mögliche Hintertür all das unbemerkbar zu machen.
Letztlich wird es die meisten Benutzer nicht davon abbringen Google weiter zu benutzen. Doch wenn es mal krachen sollte, will ich lieber auf DuckDuckGo gewesen sein (zumindest im Moment).
Ob Google nun eine Cyber-Atombombe im WWW gebaut hat oder den noch nicht ausgesetzten virtuellen T-Virus (analog dem T-Virus aus der Filmreihe “Resident Evil“), der alle infizierten Systeme in Zombies verwandelt, das mag ich nicht beurteilen wollen. Die Möglichkeit hierzu ist definitiv gegeben. Google ist heute praktisch die “Swiss Knife” des öffentlichen WWW. Sie ist ein tägliches Universalwerkzeug, kann aber bei dem heutigen Nutzungsgrad sehr schnell zu einer Waffe umgewandelt werden.
Da wundert es mich nicht, dass die Nato nun einen Richtungswechsel in die Cyber-Offensive macht. Das hatte ich ja bereits vor über einem Jahr in eines meiner Artikel vermutet und lag damit wahrscheinlich auch ziemlich richtig. Was Nato beabsichtigt, hat Google doch schon bereits: Mit einem Klick weitestgehend alles lahm legen oder ver-zombi-sieren. Um es einfacher auszudrücken: NATO = USA = NSA => GOOGLE => 1-Klickshot => Billions of Lightsout.
Hoffen wir also, dass Google nur das monetäre Interesse weiterverfolgt, wobei ich mir da schon lange nicht mehr sicher bin, ob es nur ums Geld geht.
Übrigens, wer den spannenden Vortrag von David Kriesel “SpiegelMining – Reverse Engineering von Spiegel-Online” aus dem 33. Chaos Computer Club Kongress kennt (33c3), der wird sich vorstellen können, welche Möglichkeiten des Data Minings erst recht Google mit diesem Verfahren besitzt.
Denn Google kopiert auch gerade in dieser Sekunde mehrfach das gesamte, von ihm erreichbare WWW, während sie diesen Artikel zu ende lesen (Das gleiche wäre auch im Darknet möglich).
(red)
Update (17.12.2017)
Der Fehler lässt sich in Google nicht mehr reproduzieren.
Der Grund hierfür könnte tatsächlich sein, dass die Cache-Referenzen von Google mit der Ziel-URL nicht mehr übereinstimmen, da interessanter Weise die Internetadresse jeantet.ch nun auf die physische Adresse http://vu2017.host42.ntd.ch/ umgeleitet wird. Das heisst, auch der Server Administrator hat was an seinen Weiterleitungen verändert.
Zudem hat die Jeantet Stiftung ihre Webseiten seit kurzem völlig aktualisiert.
Und warum hat der Aufruf der infizierten Seiten über DuckDuckGo nicht geklappt, während Google-User ständig auf die infizierten Seiten gelangt sind? Das lag wohl am Referring-System von Google in Verbindung mit ihren Cookies.
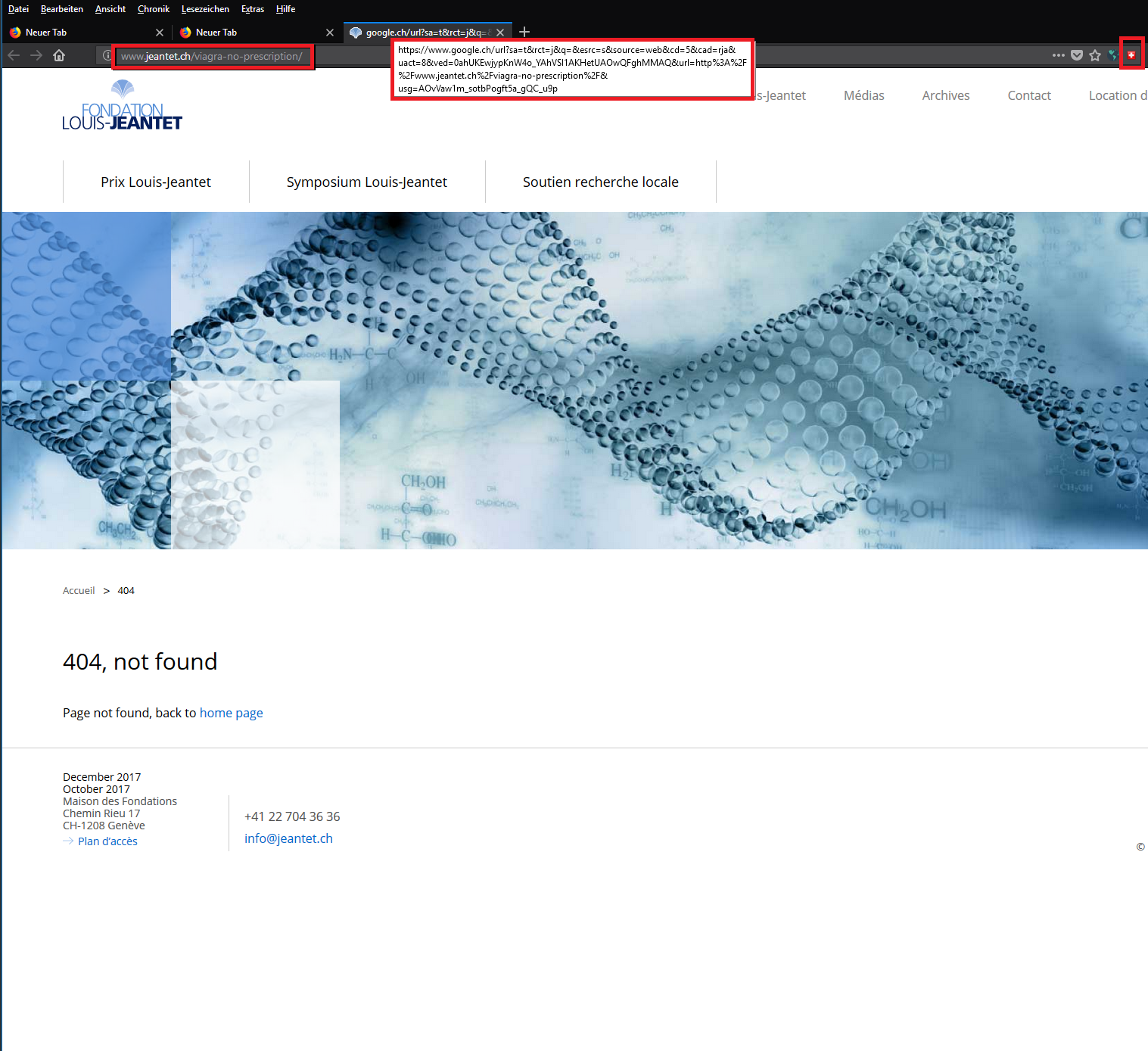
Es scheint tatsächlich, dass der Fehler am Cache der CMS Software oder am Webserver des Hosters lag. Peinlich, dass ich zuvor Google vollständig für diese Konfusion beschuldig habe (was die zuvor genannten Gefahren durch Google nicht zwangsläufig ausschliesst. Ich korrigiere, Google ist mit dran schuld! 😀
https://www.youtube.com/watch?v=5LeKM9cMcSU